What’s the Right Way to Decode a String That has Special HTML Entities in it?
This post will let you know the right way for decoding strings with special HTML entities.
What’s the Right Way to Decode a String That has Special HTML Entities in it?
To decode a string that contains special HTML entities in it, use the following methods:
Method 1: Decode a String That has Special HTML Entities in it Using “textarea” Element
Use the HTML “<textarea>” element for decoding a string that contains special HTML entities. It takes a string with special HTML entities using the “innerHTML” property. The browser automatically decodes the entities in the textarea and gives the simple plain text. For retrieving the decoded string, use the “value” property.
Example
Create a variable “encodedString” that stores a string containing special HTML entities in it:
Print the encoded string on the console:
Create an HTML element “textarea” using the “createElement()” method:
Pass the encoded string to the textarea using the “innerHTML” property:
Now, get the decoded string using the “value” attribute of the textarea and store it in a variable “decodedString”:
Finally, display the decoded string on the console using the “console.log()” method:
The output indicates that the string containing special HTML entities has been successfully decoded:

The above approach is simple and clear, and it is suitable for simple scenarios. If you try to handle complex HTML structures, it will fail. So, for that, use the “parseFromString()” Method.
Method 2: Decode a String That has Special HTML Entities in it Using “parseFromString()” Method
Another way to decode a string with special HTML entities is the “parseFromString()” method. It is a pre-built method of the “DOMParser” object. It helps to parse an XML or HTML string and then create a new DOM document object from it.
Example
First, create a new object of the “DOMParser” using the “new” keyword:
Call the “parseFromString()” method and pass the parameters “encoded string” as a complex HTML structure, and the “text/html”. It tells the method to treat the encoded string as HTML. Use the “textContent” property of the body element to get the decoded string:
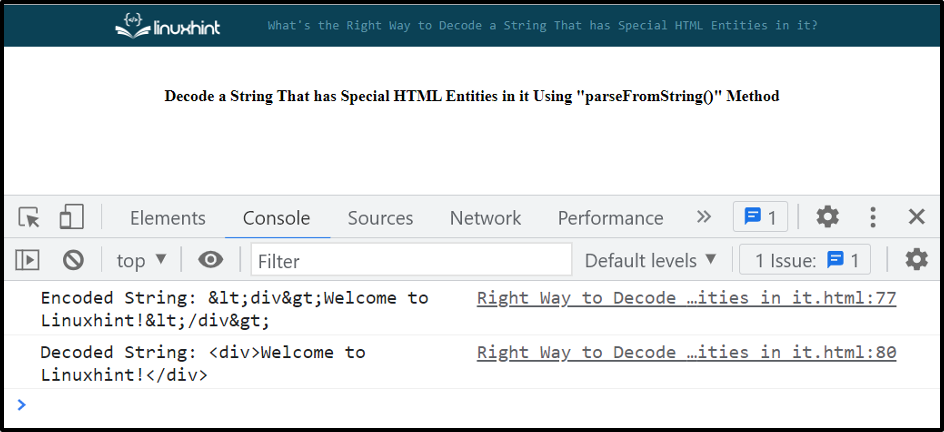
Print the decoded string on the console:
Output
We have provided all the essential instructions relevant to decoding a string with special HTML entities.
Conclusion
For decoding a string that contains special HTML entities in it, utilize the HTML element “textarea” or the
“parseFromString()” method of the “DOMParser” object. The <textarea> approach is suitable for simple scenarios while the parseFromString() method is a more robust and secure approach that can handle complex HTML structures. It is recommended to use the “parseFromString()” method to decode a string containing HTML entities. This post described the right way for decoding strings with special HTML entities.
Source: linuxhint.com