Return Top & Last Rows From PySpark Pandas DataFrame
PySpark – pandas DataFrame represents the pandas DataFrame, but it holds the PySpark DataFrame internally.
Pandas support DataFrame data structure, and pandas are imported from the pyspark module.
Before that, you have to install the pyspark module.”
Command
Syntax to import:
After that, we can create or use the dataframe from the pandas module.
Syntax to create pandas DataFrame:
We can pass a dictionary or list of lists with values.
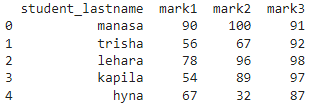
Let’s create a pandas DataFrame through pyspark that has four columns and five rows.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’],
‘mark1’:[90,56,78,54,67],‘mark2’:[100,67,96,89,32],‘mark3’:[91,92,98,97,87]})
print(pyspark_pandas)
Output:
Now, we will go into our tutorial.
There are several ways to return the top and last rows from the pyspark pandas dataframe.
Let’s see them one by one.
pyspark.pandas.DataFrame.head
head() will return top rows from the top of the pyspark pandas dataframe. It takes n as a parameter that specifies the number of rows displayed from the top. By default, it will return the top 5 rows.
Syntax:
Where pyspark_pandas is the pyspark pandas dataframe.
Parameter:
n specifies an integer value that displays the number of rows from the top of the pyspark pandas dataframe.
We can also use the head() function to display specific column.
Syntax:
Example 1
In this example, we will return the top 2 and 4 rows in the mark1 column.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’],‘mark1’:[90,56,78,54,67],‘mark2’:[100,67,96,89,32],‘mark3’:[91,92,98,97,87]})
#display top 2 rows in mark1 column
print(pyspark_pandas.mark1.head(2))
print()
#display top 4 rows in mark1 column
print(pyspark_pandas.mark1.head(4))
Output:
1 56
Name: mark1, dtype: int64
0 90
1 56
2 78
3 54
Name: mark1, dtype: int64
We can see that the top 2 and 4 rows were selected from the marks1 column.
Example 2
In this example, we will return the top 2 and 4 rows in the student_lastname column.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’],‘mark1’:[90,56,78,54,67],‘mark2’:[100,67,96,89,32],‘mark3’:[91,92,98,97,87]})
#display top 2 rows in student_lastname column
print(pyspark_pandas.student_lastname.head(2))
print()
#display top 4 rows in student_lastname column
print(pyspark_pandas.student_lastname.head(4))
Output:
1 trisha
Name: student_lastname, dtype: object
0 manasa
1 trisha
2 lehara
3 kapila
Name: student_lastname, dtype: object
We can see that the top 2 and 4 rows were selected from the student_lastname column.
Example 3
In this example, we will return the top 2 rows from the entire dataframe.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’],‘mark1’:[90,56,78,54,67],‘mark2’:[100,67,96,89,32],‘mark3’:[91,92,98,97,87]})
#display top 2 rows
print(pyspark_pandas.head(2))
print()
#display top 4 rows
print(pyspark_pandas.head(4))
Output:
0 manasa 90 100 91
1 trisha 56 67 92
student_lastname mark1 mark2 mark3
0 manasa 90 100 91
1 trisha 56 67 92
2 lehara 78 96 98
3 kapila 54 89 97
We can see that the entire dataframe is returned with the top 2 and 4 rows.
pyspark.pandas.DataFrame.tail
tail() will return rows from the last in the pyspark pandas dataframe. It takes n as a parameter that specifies the number of rows displayed from the last.
Syntax:
Where pyspark_pandas is the pyspark pandas dataframe.
Parameter:
n specifies an integer value that displays the number of rows from the last of the pyspark pandas dataframe. By default, it will return the last 5 rows.
We can also use the tail() function to display specific columns.
Syntax:
Example 1
In this example, we will return the last 2 and 4 rows in the mark1 column.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’],‘mark1’:[90,56,78,54,67],‘mark2’:[100,67,96,89,32],‘mark3’:[91,92,98,97,87]})
#display last 2 rows in mark1 column
print(pyspark_pandas.mark1.tail(2))
print()
#display last 4 rows in mark1 column
print(pyspark_pandas.mark1.tail(4))
Output:
4 67
Name: mark1, dtype: int64
1 56
2 78
3 54
4 67
Name: mark1, dtype: int64
We can see that the last 2 and 4 rows were selected from the marks1 column.
Example 2
In this example, we will return the last 2 and 4 rows in the student_lastname column.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’],‘mark1’:[90,56,78,54,67],‘mark2’:[100,67,96,89,32],‘mark3’:[91,92,98,97,87]})
#display last 2 rows in student_lastname column
print(pyspark_pandas.student_lastname.tail(2))
print()
#display last 4 rows in student_lastname column
print(pyspark_pandas.student_lastname.tail(4))
Output:
4 hyna
Name: student_lastname, dtype: object
1 trisha
2 lehara
3 kapila
4 hyna
Name: student_lastname, dtype: object
We can see that the last 2 and 4 rows were selected from the student_lastname column.
Example 3
In this example, we will return the last 2 rows from the entire dataframe.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({‘student_lastname’:[‘manasa’,‘trisha’,‘lehara’,‘kapila’,‘hyna’],‘mark1’:[90,56,78,54,67],‘mark2’:[100,67,96,89,32],‘mark3’:[91,92,98,97,87]})
#display last 2 rows
print(pyspark_pandas.tail(2))
print()
#display last 4 rows
print(pyspark_pandas.tail(4))
Output:
3 kapila 54 89 97
4 hyna 67 32 87
student_lastname mark1 mark2 mark3
1 trisha 56 67 92
2 lehara 78 96 98
3 kapila 54 89 97
4 hyna 67 32 87
We can see that the entire dataframe is returned with the last 2 and 4 rows.
Conclusion
We saw how to display the top and last rows from the pyspark pandas dataframe using head() and tail() functions. By default, they return 5 rows.head(), and tail() functions are also used to get the top and last rows with specific columns.
Source: linuxhint.com