Pandas Reshape
This tutorial will show you a thorough overview of how to reshape Pandas Series or DataFrame utilizing multiple examples.
How to Reshape Pandas Series in Python?
In Python, the “series.values.reshape()” method is used to reshape the Pandas series based on the specified dimension. We can add or remove dimensions in an array by using this method.
Syntax
This method retrieves the ndarray with the shape values if the shape corresponds exactly to the present shape.
Example: Reshape Pandas Series Using “Series.values.reshape()” Method
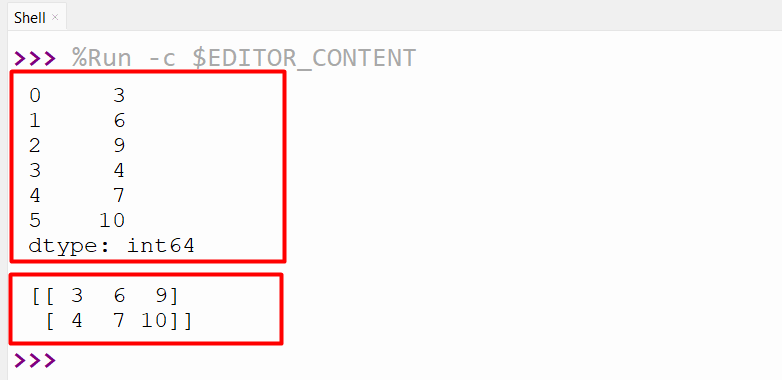
In this example code, firstly we import the “Pandas” library and create the Pandas series. Next, the “Series.values” attributes of the Series object retrieve the NumPy array containing the same values as the Series object. After that, the “reshape()” method is called on the array object. This method accepts the specified dimension and retrieves the two-dimensional array with two rows and three columns:
ser1 = pandas.Series([3, 6, 9, 4, 7, 10])
print(ser1, ‘\n‘)
print(ser1.values.reshape((2, 3)))
The input series object has been reshaped successfully:
How to Reshape Pandas DataFrame in Python?
To reshape Pandas DataFrame various methods are used in Python, such as “pandas.pivot()” and “pandas.melt()” methods. These specified methods are used to convert the structure of a given DataFrame from wide to long format.
Let’s start with the “pandas.pivot()” method!
Example 1: Using “pandas.pivot()” Method to Reshape Pandas DataFrame
The “pandas.pivot()” method is used to reshape the DataFrame data from a long to wide format.
Syntax
Here, the “index” parameter specifies the column used as the index, the “columns” parameter specifies the new column, and the “values” parameter contains the new column value.
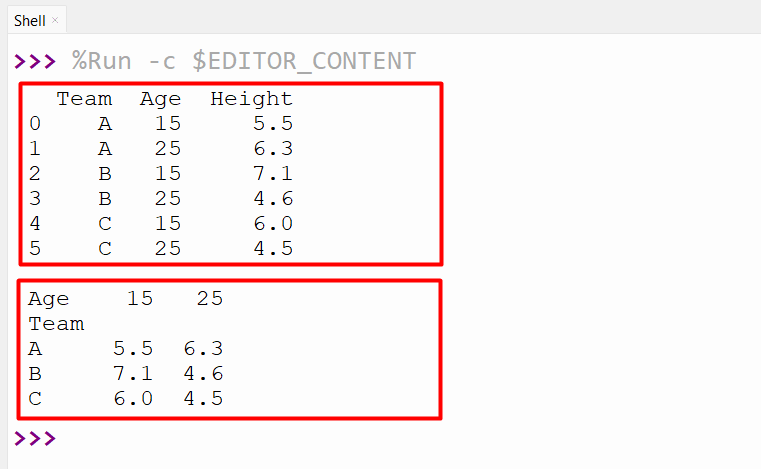
In the below code, the “pandas.pivot()” method reshapes the data by creating a new index from the values in the specified column “Team”, and creating new columns from the unique values in another column “Age”. The values in the DataFrame are filled with the values from a third column “Height”:
df=pandas.DataFrame({‘Team’: [‘A’, ‘A’, ‘B’, ‘B’, ‘C’, ‘C’],
‘Age’: [15, 25, 15, 25, 15, 25],
‘Height’: [5.5, 6.3, 7.1, 4.6, 6.0, 4.5]})
print(df, ‘\n‘)
df = pandas.pivot(df, index=‘Team’, columns=‘Age’, values=‘Height’)
print(df)
The method retrieves the DataFrame with three rows (one for each team) and two columns (one for each age group):
Example 2: Using “pandas.melt()” Method to Reshape Pandas DataFrame
Now, we can use the “pandas.melt()” method to reshape the DataFrame from a wide/broad to a long format. This method is utilized when we have multiple columns that represent multiple variables and stack them into a single column.
Syntax
Here, the “id_vars” parameter specifies the columns that remain unchanged while the “value_vars” parameter is the columns that should be melted down.
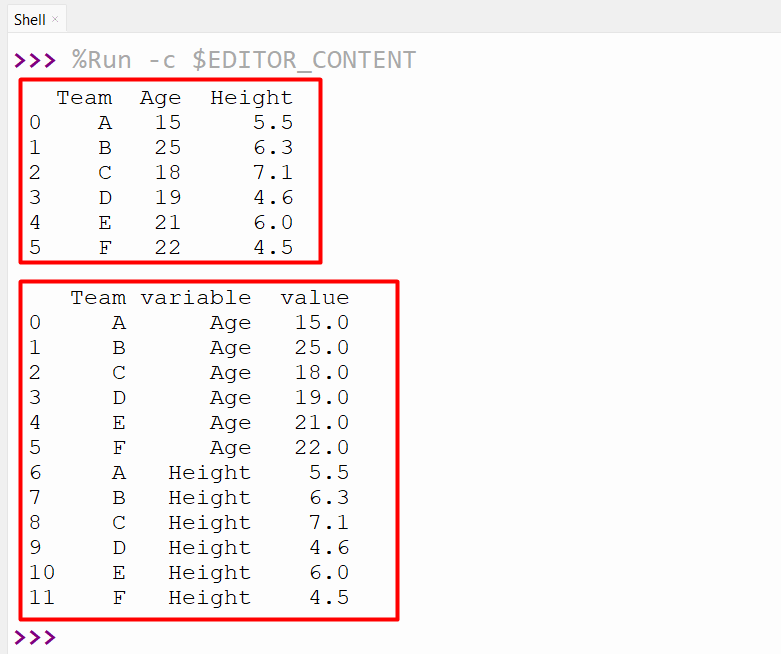
In the below code, the “pandas.melt()” reshape the DataFrame and retrieve the new DataFrame with four columns “Index”, “Team”, “Variable” and “Value”. Here, the “id_vars=” parameter is used to keep the “Team” column as identifiers, while the “value_vars” parameter is used to melt the “Age” and “Height” columns:
df=pandas.DataFrame({‘Team’: [‘A’, ‘B’, ‘C’, ‘D’, ‘E’, ‘F’],
‘Age’: [15, 25, 18, 19, 21, 22],
‘Height’: [5.5, 6.3, 7.1, 4.6, 6.0, 4.5]})
print(df, ‘\n‘)
df = pandas.melt(df, id_vars=[‘Team’], value_vars=[‘Age’, ‘Height’])
print(df)
The given DataFrame has been reshaped by transforming columns “Age” and “Height” into rows:
Conclusion
The “series.values.reshape()”, “pandas.pivot()” and “pandas.melt()” methods are used to reshape the Pandas Series and DataFrame. The dimensions are passed to the “Series.values.reshape()” method to convert the specified Series to an array and then reshape the array. The “pandas.pivot()” and “pandas.melt()” methods convert the wide format DataFrame to long format DataFrame. This guide presented a comprehensive tutorial on Pandas reshape utilizing numerous examples.
Source: linuxhint.com