SQLite SELECT DISTINCT Statement
SQLite is a framework that defines a transaction-oriented SQL database system that is self-contained and requires no deployment. SQLite’s codebase is in the mainstream, which means it could be used for every intent, personal or professional. SQLite is perhaps the most extensively used database worldwide, including an uncountable number of applications and some elevated initiatives.
SQLite is a SQL database system for integrated devices. SQLite will not include a discrete server component like many other Database systems. SQLite writes data to regular database files natively. A single database file consists of a whole SQL database, including many tables, indexes, initiates, and columns. We can easily replicate a database across 32-bit and 64-bit operating systems because the file type of the database file type is multidimensional. SQLite is a widely used statistical File System because of these attributes.
The “DISTINCT” term in SQLite can evaluate the “SELECT” command’s dataset and remove all duplicate values, ensuring that the retrieved entries are from a valid set of the “SELECT” query. When deciding whether or not a record is a duplicate, the SQLite “DISTINCT” term analyzes just one column and data provided in the “SELECT” command. In the SQLite “SELECT” query, when we declare “DISTINCT” for a single column, the “DISTINCT” query would only retrieve unique results from that defined column. When we can apply a “DISTINCT” query for more than one column in the SQLite “SELECT” command, “DISTINCT” can assess duplicate data using a combination of each of these columns. NULL variables are taken as redundancies in SQLite. Thus, if we are using the “DISTINCT” query on a column with NULL entries, this will only retain a single row containing NULL data.
Examples
With the help of different examples, we will discover how to use the SQLite DISTINCT term, SQLite DISTINCT by a SELECT query, and SQLite SELECT unique on several columns to acquire unique values from a specific table.
Any compiler must be installed to run the queries. We installed the BD Browser for SQLite software here. First, we selected the “New database” option from the context menu and established a new database. It would be placed in the SQLite database files folder. We run the query to form a new database. Then, using the specialized query, we’ll construct a table.
Creation of the Table
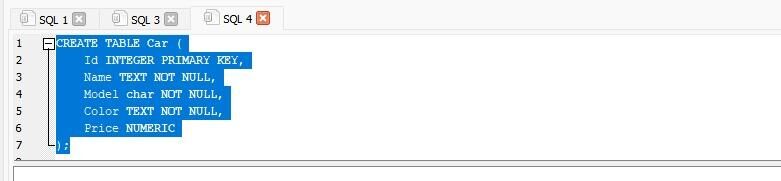
Here, we will create the table of “Car” and specify the data in it. The table “Car” contains the columns “Id”, “Name”, “Model”, “Color”, and “Price”. The column “Id” has an integer data type, “Name” and “Color” have a text data type, “Model” has a character data type, and “Price” has a numeric data type.
|
1
2 3 4 5 6 7 8 9 10 |
CREATE TABLE Car (
Id INTEGER PRIMARY KEY, ); |
The following output shows that the query of “CREATE” is successfully executed:
Insertion of Data
Now, we want to insert the data into the table “Car”, so we execute the query of “INSERT”.
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
INSERT INTO Car (Id,CompanyName,Model,Color,Price) VALUES (1,‘Tesla ‘, ‘Cybertruck’, ‘Gray’,‘39999’),
(2,‘Mazda’, ‘Mazda CX-9’, ‘White,Gray,Black’,‘34160’), (3,‘Toyota ‘, ‘Corolla Cross’, ‘black,blue’,‘61214’), (4,‘Honda’, ‘Accord’, ‘red,white’,‘54999’), (5,‘Jaguar’, ‘I-Pace’, ‘green,black,white’,‘55400’), (6,‘Mitsubishi’, ‘Outlander’, ‘yellow,gray’,‘35500’), (7,‘Volvo’, ‘XC40’, ‘silver,black’,‘62000’), (8,‘Lexus’, ‘GX’, ‘purple’,‘45000’); |
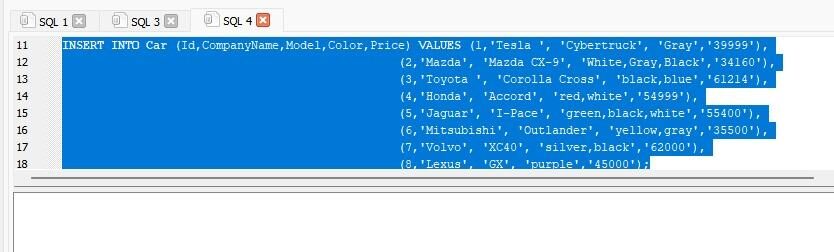
We successfully inserted the data, including Id, CompanyName, Model, Color, and Price of different cars, in the table.

Use “SELECT” Query
We can retrieve the entire data of the table by using the “SELECT” query.
|
1
|
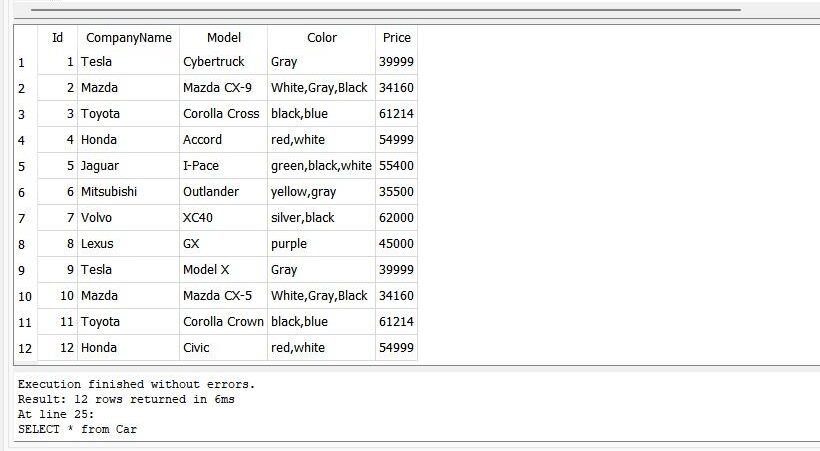
>> SELECT * FROM Car
|

After running the previous query, we can get all data of the 12 cars.
Use the “SELECT DISTINCT” Query on One Column
The “DISTINCT” term in SQLite is being used in combination with the “SELECT” query to remove all duplicate entries and retrieve only distinct values. Maybe, there are instances when a table has several duplicate entries. It makes better sense to acquire the distinct items rather than duplicate data when retrieving these data.
|
1
|
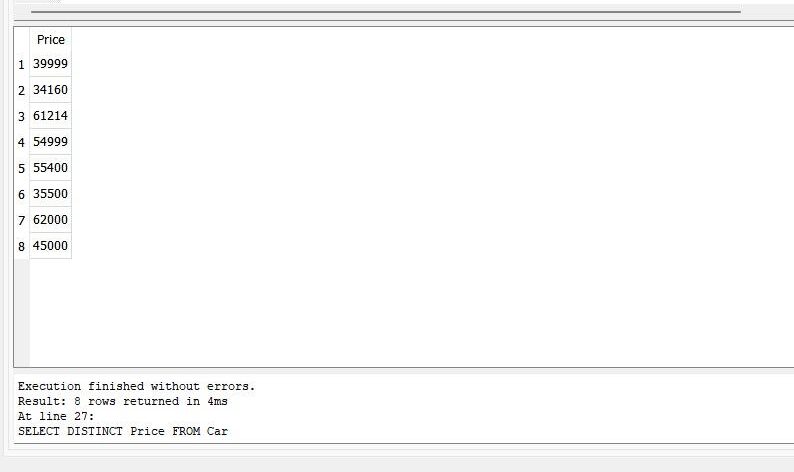
>> SELECT DISTINCT Price FROM Car
|

There is data of 12 cars in the table “Car”. But, when we apply “DISTINCT” along with “SELECT” query on the column “Price”, we can get the unique prices of the cars in the output.
Use the “SELECT DISTINCT” Query on Multiple Columns
We can apply the “DISTINCT” command on more than one column. Here, we want to delete the duplicate values of the columns “CompanyName” and “Price” of the table. So, we utilize “DISTINCT”.
|
1
|
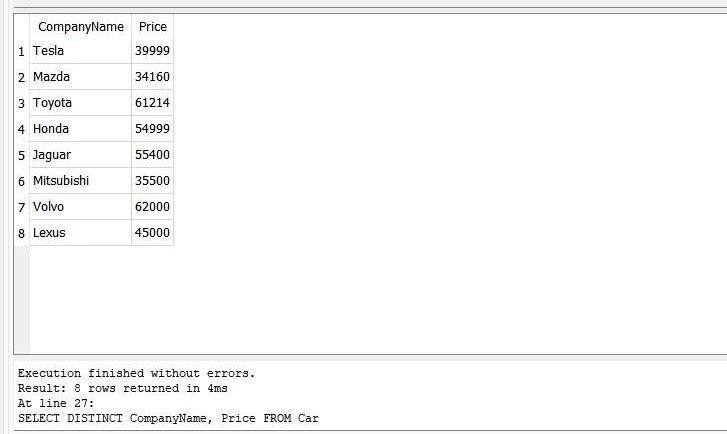
>> SELECT DISTINCT CompanyName, Price FROM Car
|

After executing the query, the result shows the unique values of the “price” and unique names of the “CompanyName”.
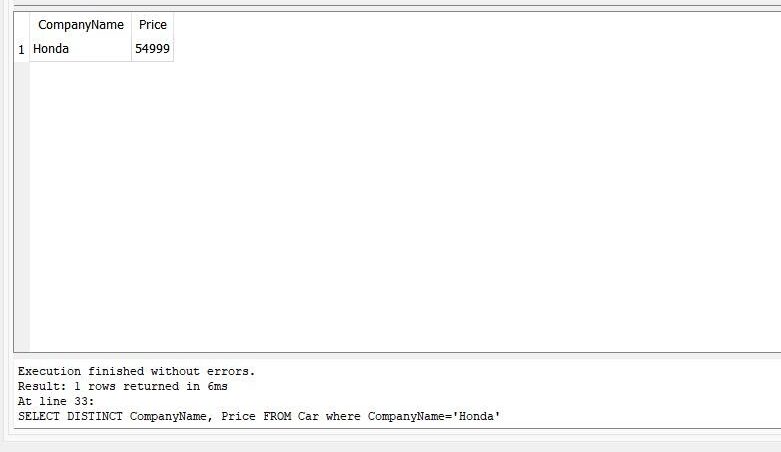
In this case, we employ the “DISTINCT” query on the column “CompanyName” and “Price” of the table “Car”. But we specify the “CompanyName” in the query using the “WHERE” clause.
|
1
|
>> SELECT DISTINCT CompanyName, Price FROM Car WHERE CompanyName=‘Honda’
|

The output is shown in the following figure:
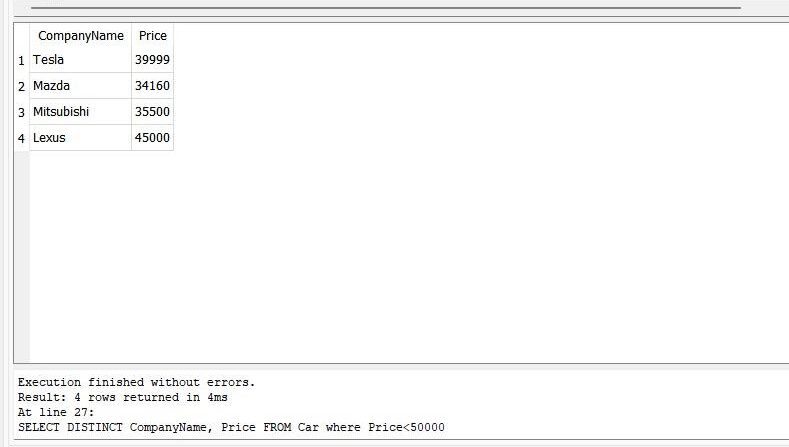
Here, we utilize the “SELECT DISTINCT” query and the “WHERE” clause. In this query, we have specified the condition in the “WHERE” clause, which shows that the price of the car must be less than 50000.
|
1
|
>> SELECT DISTINCT CompanyName, Price FROM Car WHERE Price<50000
|

The query returns four rows. There are several duplicate rows in the columns “CompanyName” and “Price”. We delete these duplicate values with the help of the “DISTINCT” statement.
Use the “SELECT DISTINCT” and “BETWEEN” Clauses
The “DISTINCT” clause is applied just after the “SELECT” word. Then, we use the “DISTINCT” and “BETWEEN” clauses together in this example. The “BETWEEN” clause shows the condition that the price of the car will be between 20000 and 50000.
|
1
|
>> SELECT DISTINCT CompanyName, color, Price FROM Car WHERE Price BETWEEN 20000 AND 50000
|

The outcome shows the “CompanyName” and the “Color” of those cars whose price lies between 20000 to 50000.

Conclusion
We have explored how to employ the SQLite “SELECT DISTINCT” statement to delete duplicate entries from the data set in this article. In the SELECT query, the “DISTINCT” command is an optional feature. If the single expression is specified in the “DISTINCT” statement, the query provides the expression’s distinct values. Whenever the “DISTINCT” statement contains multiple expressions, the query would provide a specific set for the expressions mentioned. The “DISTINCT” command in SQLite will not avoid NULL values. As a result, if we use the “DISTINCT” command in the SQL query, NULL will appear as a distinct element in the outcome.
Source: linuxhint.com