Python Urlparse()
What is Python “urlparse()”?
Python “urlparse()” function of the “urllib.parse” module is used to parse a URL and return a named tuple that contains the individual components of the URL. The “urlparse()” function can extract information from a URL including a “scheme”, “network location”, “path”, “query parameters”, and “fragment identifier”.
Syntax
In the above syntax:
- The mandatory “urlstring” parameter is the URL string that you want to parse.
- The “scheme” parameter specifies the default URL scheme to be used if the parsed URL string does not contain a scheme. The default value is an empty string (‘ ‘).
- The “allow_fragments” parameter corresponds to a boolean value that specifies whether the parser should handle fragment identifiers(the part of the URL after the “#” character). The default value is “True”.
Let’s understand the usage of the Python “urlparse()” function with the help of various examples:
Example 1: Applying the “urlparse()” Function to Parse a Simple URL
The below code is used to parse a simple URL:
url = ‘https://www.example.com/path/to/page.html’
parsed_url = urlparse(url)
print(parsed_url.scheme)
print(parsed_url.netloc)
print(parsed_url.path)
In the above code:
- The “urllib.parse” module is imported.
- The “urlparse()” function takes a “URL” string “url” as an argument and returns a named tuple containing its components.
- The parsed URL components are then printed using the “print()” function.
- The multiple print statements are used to print the “scheme”, the “netloc”, and the “path” of the URL, respectively.
Output
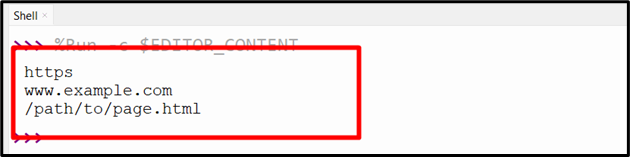
The above snippet verified that the URL string has been parsed into its components appropriately.
Example 2: Applying the “urlparse()” Function to Parse a URL With Query Parameters
The following code can be used to extract query parameters from a URL string and store them in a dictionary for further processing:
url = ‘https://www.example.com/search?q=python&sort=recent’
parsed_url = urlparse(url)
print(parsed_url.query)
query_params = dict(qc.split("=") for qc in parsed_url.query.split("&"))
print(query_params)
In the above code snippet:
- The “urlparse” function from the “urllib.parse” module is imported.
- After that, the applied “urlparse()” function takes a “URL” string named “url” as an argument and likewise, returns a named tuple containing its components. The parsed URL is stored in the variable “parsed_url”.
- The “print()” statement prints out the “query” string of the URL.
- The dictionary called “query_params” is created by splitting the query string into “key-value” pairs via the “split()” method and then splitting each key-value pair using the “=” sign.
Output
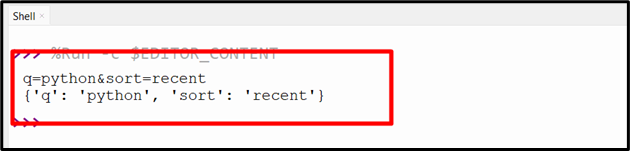
The above output successfully extracted query parameters from a URL string.
Example 3: Applying the “urlparse()” Function to Parse a URL With Fragment Identifier
The following code block is used to parse the URL with fragment identifier:
url = ‘https://www.example.com/about#history’
parsed_url = urlparse(url)
print(parsed_url.fragment)
Based on the above lines of code:
- The “urlparse()” function is applied to have the argument “url” and the returned value is assigned to a variable named “parsed_url”.
- The fragment identifier of the URL is printed using the “.fragment” attribute of the returned object.
Output
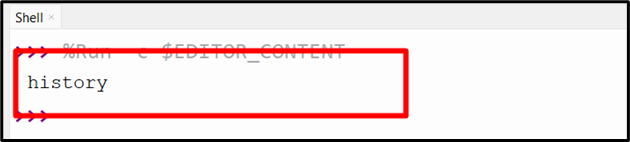
The fragment component/identifier of the parsed url object, i.e., “history“, is retrieved accordingly.
Conclusion
In Python, the “urlparse()” function is used to parse URLs and extract specific parts of the URL such as the “scheme”, “network location”, “path”, “query parameters”, and “fragment identifier”. The syntax, parameters, and usage of the “urlparse()” function are explained utilizing multiple examples. This article explains an in-depth guide on Python’s “urlparse()” function and how to use it to parse different types of URLs.
Source: linuxhint.com