Python Count Duplicate in the List
The content of this guide is given below:
- Method 1: Using List to Set Conversion
- Method 2: Using the List Comprehension and count() Method
- Method 3: Using the List Comprehension With If-not-in Condition
Let’s start with the first method right away!
Method 1: Using List to Set Conversion
A list in Python can contain duplicates, meaning that there is no uniqueness like the one found in Python sets. Therefore, an easy way to detect if there are any duplicates inside a python list is to convert it into a set and compare the size of both.
To demonstrate this, start by creating a list in Python by using the following code:
After that, use the set() method to convert this list into a set and store it inside a separate variable:
Print the number of elements of both by using the len() method:
print("Elements in Set: ",len(setVar))
When this code is executed, it produces the following results on the terminal:
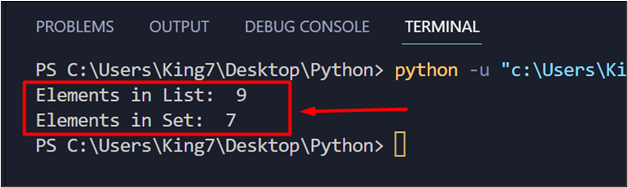
According to the output, the number of elements in the list is 9 and 7 for the set. This means that there are a total of two duplicates in the List. But, instead of manually calculating duplicates, you can also use the following line:
The complete code snippet with this new print statement is:
setVar = set(listVar)
print("Number of Duplicates in List ",len(listVar)-len(setVar))
When this code is executed, it produces the following result on the terminal:
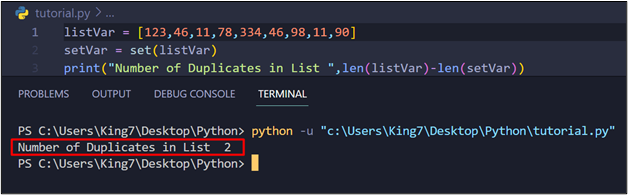
As you can see from the output image, there are a total of two duplicates in the list.
Method 2: Using the List Comprehension and count() Method
Another method of printing out the duplicates of a list is by using the list comprehension method to fetch each value from the list and then using the count() method to check its count within the list. If the result of the count() method is greater than one, then you can add that element to a list of duplicates.
To demonstrate the working of this method, take the following code:
duplicateVar =[]
for x in listVar:
if listVar.count(x) > 1:
duplicateVar.append(x)
print("The duplicates found in the list are: ", duplicateVar)
When this code is executed, it produces the following result on your terminal:

As you can see from the output, the values “46” and “11” were present two times each.
Method 3: Using the List Comprehension With If-not-in Condition
Another method of finding duplicates in a list is by using the list comprehension and applying the if-not-in condition.
Take the following code snippet for this method:
uniqueListVar = []
duplicateListVar = []
for x in listVar:
if x not in uniqueListVar:
uniqueListVar.append(x)
else:
duplicateListVar.append(x)
print("The List of Unique Elements is: ", uniqueListVar)
print("The duplicates found in the list are: ", duplicateListVar)
In this code snippet:
- Two new lists are created, one to store each unique value, and one to store each repeating/duplicate value
- Each element is checked against the values stored inside the unique value list, and if it doesn’t already exist there, then it is appended to it.
- If it already exists there, then it is appended to the list of duplicate values.
- At the end, print both lists on the terminal using the print() method
When this code is executed, it produces the following result on your terminal:
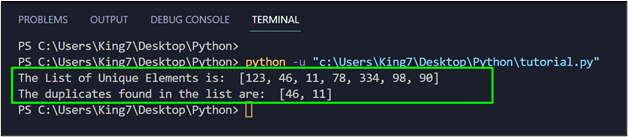
From the output, it can be seen that the values “46” and “11” were duplicates and therefore, only one of their instances is left in the list of unique values.
Conclusion
To find duplicates in a list, the user can utilize different approaches that include converting the list into a string, using the list comprehension with the count() method, or using the if-not-in condition with the list comprehension. However, the fastest method to remove the duplicates from the list is the conversion of the list into a set.
Source: linuxhint.com