PostgreSQL Group By Examples
PostgreSQL offers the GROUP BY clause to allow the users to form groups of rows when working with the SELEC statement. You can form groups of rows from single or multiple columns.
The GROUP BY clause can be used with or without different aggregate functions. This post guides you in understanding how to work with the PostgreSQL GROUP BY clause. We will give numerous examples to ensure that you are comfortable working with it. Let’s begin.
PostgreSQL GROUP BY Syntax
The GROUP BY clause is used with the SELECT statement to form groups. Its syntax is as follows:
In the syntax, you start by writing the “select” statement. Next, you must specify the column(s) from which you wish to form the groups of rows. If using an aggregate function such as COUNT(), MAX(), SUM(), AVG(), etc., you must specify it and the column that you target to apply the aggregate function.
You must then specify the table that you are using, and the GROUP BY statement follows with the selected column(s).
Let’s have examples.
Example 1: GROUP BY without the Aggregate Function
The aggregate function is optional. For this case, we use the following table for our examples:
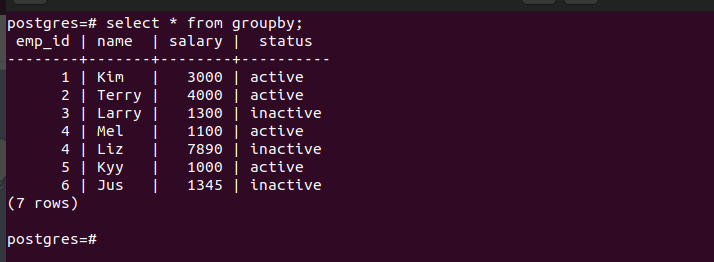
Here’s a simple GROUP BY query that uses a single column to group the status that is used in the table. From the output, we see that it returns two rows:
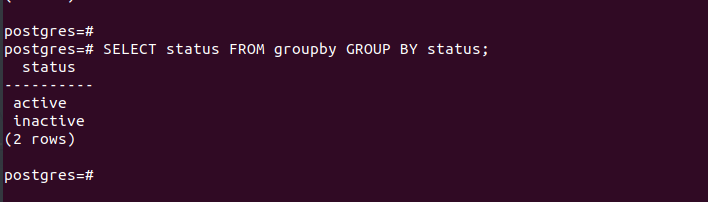
The command selects the “status” column from our table and groups the selected column into rows. In this case, we only have the active or inactive options; the two rows are returned.
Example 2: GROUP BY with SUM()
For this example, we return a sum of the “emp_id” column. Still, we select the “status” column for the grouping. By running the command in the following image, we can see that it sums the emp_id values for each entry to get the total active and inactive rows:
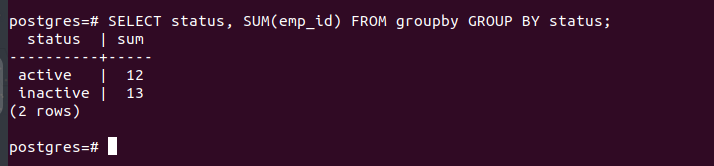
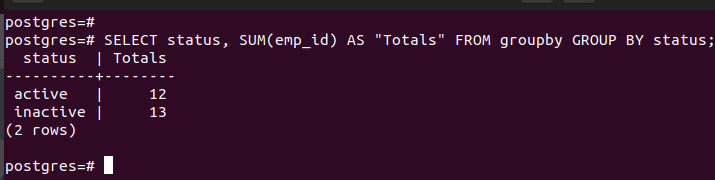
Note that the new row that is formed uses a name which is associated with the aggregate function. However, you can specify what name to use. For instance, the following example specifies the name using the AS statement:
Example 3: GROUP BY with COUNT()
Unlike SUM(), the COUNT() returns the number of instances depending on the selected column. For this example, we use COUNT() to return a row which contains the number of times that the status column is represented.
The selected column is “status”. Thus, the output returns the number of times that each instance of the value in the “status” column appears.
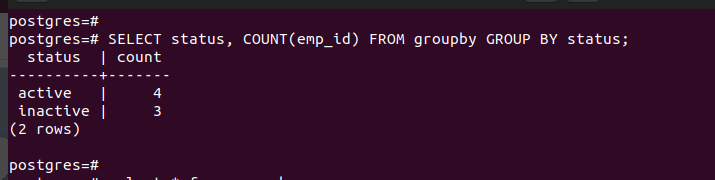
You can apply this example when you want to count the instances that a given value appears in a particular column in your table.
Example 4: GROUP BY with Multiple Columns
So far, we’ve only seen how to select a single column when working with the GROUP BY clause. However, you can select multiple columns by separating them with commas. The selected columns must also be specified after the GROUP BY statement.
In this example, we select the “name” and “salary” columns:
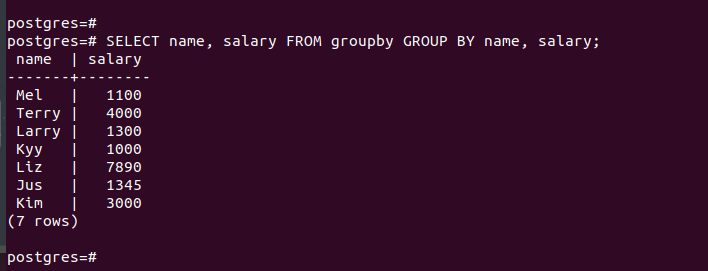
Example 5: GROUP BY Clause Combined with Other Clauses
PostgreSQL supports different clauses. When working with the GROUP BY clause, combining it with other clauses such as ORDER BY is possible.
This example selects the different columns and specifies the SUM(). Moreover, we order the arrangement in descending order using the ORDER BY clause. The output shows the list of names on our table and their status which are arranged in descending order based on the salary column:
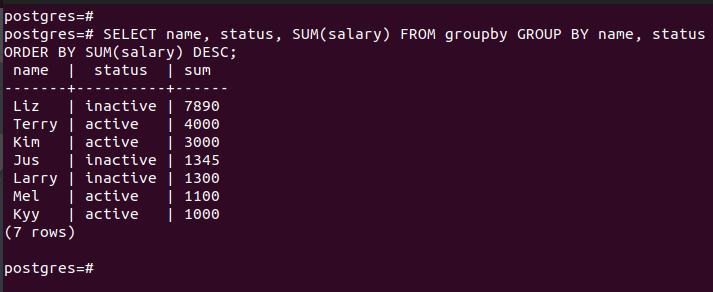
With that, you’ve seen how to use the GROUP BY clause on your PostgreSQL database for different activities. Combining the GROUP BY clause with other clauses creates specific queries.
Conclusion
When working with the SELECT statement, the GROUP BY clause is ideal when you want to group the rows in your table. This tutorial presents the different examples of working with the GROUP BY clause. Follow the presented examples and use them to get comfortable with the PostgreSQL GROUP BY clause.
Source: linuxhint.com