Pandas Vlookup
“Pandas” is a great language to perform the analysis of data because of its great ecosystem of data-centric Python packages. That makes the analysis and the import of both factors easier. The “vlookup” stands for the “vertical lookup”. It is used to merge the two different tables in the DataFrame where there should be some common attributes between them (the two tables). As an output, we will get a single table that consists of the data from both the common tables. This is similar to the one lookup function used in “excel”. We will implement all of the possible methods in which the Pandas vlookup is used. For the execution of the codes, we will use the “Spyder” which is a software that is written in “Python” in a friendly language.
Syntax:
The provided syntax is used for the vlookup in Pandas. We will do it using the “merge” function of Pandas. The “df” in the syntax is an abbreviation of the “dataframe”. The “pd” is the Pandas library and the “dot” merge function with it. It does the work of matching the similarities between the two columns in the DataFrame. Then, in the bracket, we can write the DataFrame names with the method that we want to perform. We will do all of the methods: “inner”, “left”, and “right.
Following are the ways in which the Pandas vlookup method can be performed. We will do it with the examples for a better understanding.
-
- Vlookup function using merge (inner join)
- Vlookup function using merge (outer join)
- Vlookup function using merge (right join)
- Vlookup function using merge (left join)
Creating a DataFrame for the Example Implementation of Pandas Vlookup
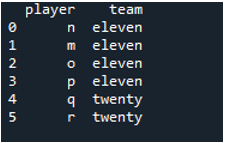
To create a DataFrame, open the “Spyder” tool as we will use that for the examples. We first import the library of Pandas as “pd”. The DataFrame consists of the “players” and the “team”. The players are “n”, “m”, “o”, “p”, “q” and “r”. And the teams are “eleven” and “twenty”. That’s how the DataFrame is created with the given print statement.

The output displays the created DataFrame as given in the following code:
Creating Another DataFrame for the Pandas Vlookup Example Execution
Here, we will create another DataFrame so that doing the application is possible. We are going step by step so that there is a clear understanding of the Pandas vlookup. The DataFrame consists of the “players” and the “points”. The players are “36”, “85”, “44”, “55”, “35”, and “25”. Then, the “print” DataFrame statement is passed for the creation of the DataFrame that is shown on the output console.
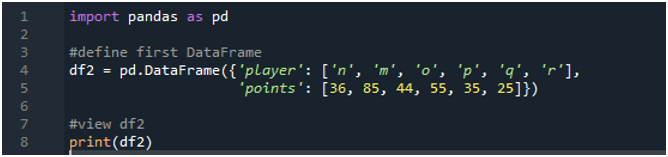
The output shows another DataFrame created having the data inserted in the code:
Since we created two separate DataFrames, we now use them for impleto implement the vlookup function.
Example 1: Vlookup Function Using Merge (Left Join)
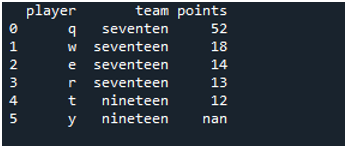
In this instance, we will perform the vlookup function using the merge join. The “df” consists of the players as “q”, “w”, “e, “r”, “t”, and “y” and the teams “seventeen” and “eighteen”. The second DataFrame has the points “52”, “18”, “14”, “13”, “12”, and “11”. The vlookup function looks up to the values in the DataFrame tables which column is matching. The “left” join operation provides all the rows from “first” dataframe and does the matching from the “second” checking which rows are not matched so that those values are replaced as “NaN”.
The NaN stands for “not a value” which means that there is no value assigned there. As we can see, the “players” is the common category among the two DataFrames. So, the on condition fulfills on it and the left join is on where this example is moving.
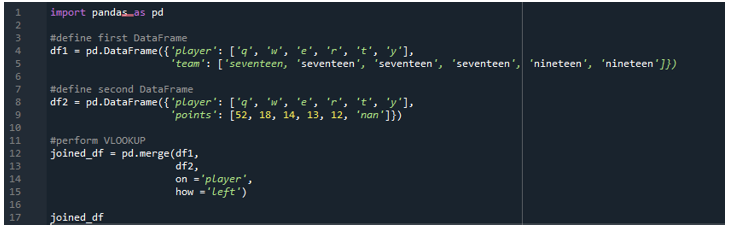
The display shows the vlookup DataFrame in Pandas, as the players follow up with the information of the team and the points, respectively.
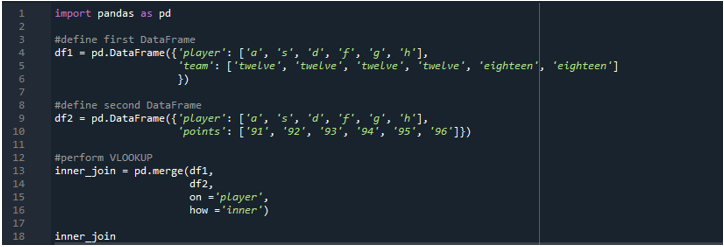
Example 2: Vlookup Function Using Merge (Inner Join)
Here, we will perform the Pandas vlookup with the merge inner join. The DataFrame has the players “a”, “s”, “d”, “f”, “g”, and “h”. Both DataFrames have the same player’s name. The “df1” consists of the team as “twelve and “eighteen”. Whereas, the “df2” has points of the players like “91”, “92”, “93”, “94”, “95” and “96”. The method that we use in this example for the vlookup function is the inner join which is used to execute the output of only those columns where the condition is satisfied in both of the resulting columns. We specify the keyword “inner” for the performance in the DataFrame.
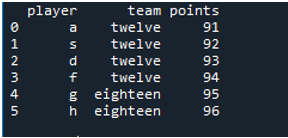
The results show the inner join performed as we see the Pandas vlookup function is represented.
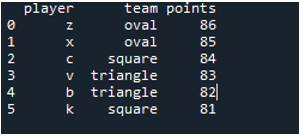
Example 3: Vlookup Function Using Merge (Right Join)
In example 1, we did the left join operation for the vlookup in Pandas. Here, we will do an example of the Pandas vlookup using the merge “right” join, which is almost homogeneous as the “left join”. The “df” comprises the players like “z”, “x”, “c”, “v”, “b, and “k” in both the DataFrames. The “df1” involves the teams like “oval”, “square” and “rectangle” where the other df has the points like “86”, “85”, “84”, “83”, “82” and “81” individually. The specification of the right join should be with the merge bracket revolving in the code.

The display shows the right join functioning DataFrame of the Pandas vlookup function, which is similar to the Pandas join merge “left” operation performed in the DataFrame for the Pandas vlookup.
Example 4: Vlookup Function Using Merge (Outer Join)
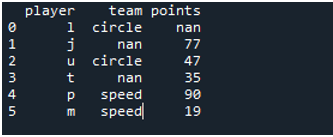
Here, we will execute the outer join function for the Pandas vlookup. The DataFrame is composed of the data as a player for both the dataframe as “l”, “j”, “u”, “t”, “p”, and “m”. The “df1” consists of the team as “circle” and “speed”. The “df2” consists of the points “77”, “47”, “35”, “90”, and “19”. The outer join that we use here is for the usage of providing the display DataFrame having both the DataFrames whose value are matching, and the no assigned values are shown as “NaN”.
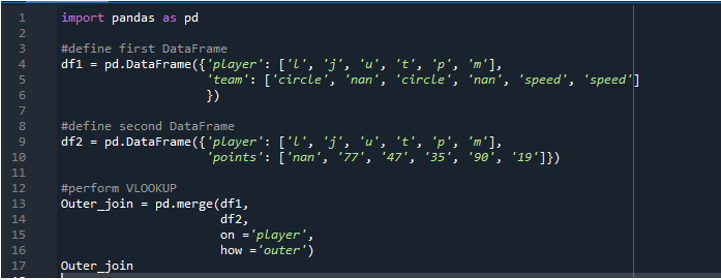
The output displays the outer join method of the Pandas vlookup function. The NaN in the display is the not assigned values.
Conclusion
The Pandas vlookup using the merge() operation makes it easier to perform the “vlookup” function in the “vlookup style”. We performed all of the methods in which the Pandas vlookup can be used. We have done this using the merge functionalities of “inner join”, “outer join”, “left join” and the “right join” methods. All of the methods have a great performance depending on the situations in which the Pandas vlookup can be used for. The Pandas vlookup came up as convenient as we can see the DataFrame “data” all managed and represented well. All the extra columns were omitted by writing only once they are common in the DataFrame. The values should be alarming which makes any analysis performance for the further evaluation of data the best and easy as it can be.
Source: linuxhint.com