Pandas to records
The “pandas” library in Python is popular for data manipulation and analysis. It provides numerous functions and methods that allow users to transform and analyze the data quickly. The “to_records()” method is one such method that assists in managing the contained data effectively. In this Python tutorial, we will discuss the syntax, parameters, return value, and examples of Pandas’ “to_records()” method in detail.
Pandas “to_records()” in Python
The pandas “to_records()” is a method that is used to transform/convert a “pandas” DataFrame into a specified “numpy” record array. A record array is a type of numpy array that allows the elements to be accessed using named fields, similar to a database table or a spreadsheet.
Syntax
In the above syntax, “DataFrame” refers to the Pandas DataFrame object that we want to convert to a numpy array.
Parameters
The “to_records()” method takes two optional parameters: “index” and “column_dtypes”.
- index: This parameter corresponds to a boolean value that indicates whether to include the DataFrame index in the output. By default, it is set to “True”.
- column_dtypes: This parameter is used to specify the data types of the columns in the output array. It takes a dictionary with column names as “keys” and data types as “values”. The “pandas” will attempt to infer the data types automatically if this parameter is not specified.
Return Value
The “to_records()” method returns a numpy “ndarray” object that represents the pandas DataFrame. The format of the output depends on the parameters passed to the method. If the index is “True”, the result will include the DataFrame index as the first column. If “column_dtypes” is specified, the output will have the columns of specified data types. The data type will be automatically inferred by pandas if this is not the case.
Let’s understand this method with the help of the following examples:
Example 1: Converting a “pandas” DataFrame to a “numpy” Array Using the “to_records()” Method
This code demonstrates the working of the Pandas “to_records()” method to convert a pandas DataFrame into a numpy record array:
df = pandas.DataFrame({'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'Salary': [50000, 60000, 70000, 80000]})
array = df.to_records(index=False)
print(array)
In the above code:
- First, the “pandas” library is imported and a DataFrame named “df” is created with three columns.
- Next, the “to_records()” method is applied to the DataFrame “df” to convert it into a record. The “index=False” parameter excludes the DataFrame index from the record array.
Output
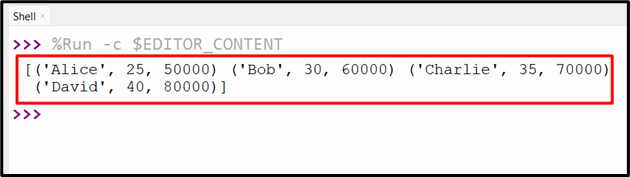
In the above output, the record array is retrieved that needs to be named for each column, like a structured array.
Example 2: Allocating a Column Name in the Converted Array Using the “to_records()” Method
The “column_dtypes” parameter can be used to allocate a column name(of the specified data type) to the numpy array obtained in the previous example:
import numpy
df = pandas.DataFrame({'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Age': [25, 30, 35, 40],
'Salary': [50000, 60000, 70000, 80000]})
array = df.to_records(index=False, column_dtypes={'Name': 'S10', 'Age': numpy.int32, 'Salary': numpy.float32})
print(array)
In the above code block:
- This code is similar to the previous example, with an inclusion of a parameter in the “to_records()” method, which specifies the data types of the columns in the resulting numpy record array.
- Likewise, a DataFrame named “df” is created and the “to_records()” method is applied to the DataFrame “df” to convert it into a numpy record array.
- The “column_dtypes” parameter is used to specify the column’s data types in the resulting record array.
- Here, the “Name” column is allocated the data type as “S10”, which means it is a string column with a maximum length of 10 characters.
- The “Age” column is assigned the data type “int32”, which indicates that it is an integer column with “32”-bit precision.
- The “Salary” column comprises the data type of “float32”, which corresponds to a floating-point column with 32-bit precision.
Output
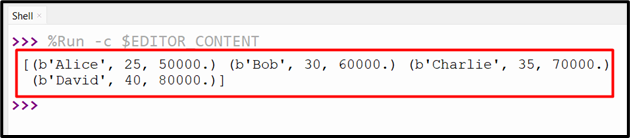
This output displays the numpy record array containing the data in the DataFrame and the column name in accordance with the specified data types.
Conclusion
The pandas “to_records()” method converts a DataFrame to a numpy record array, which can be exported to other applications. The method allows customizing the index, column names, and data types of the record array. It also preserves the original DataFrame’s column names and data types, which is useful for data analysis. This blog explained the working of the pandas’ “to_records()” method.
Source: linuxhint.com