Pandas to Dictionary
A dictionary is a way of storing information in Python. It has keys and values that are related to each other. Sometimes in Python, we may want to convert Pandas DataFrame into a different format, such as a dictionary. The “DataFrame.to_dict()” method converts the DataFrame to a Dictionary in Python.
This tutorial will give you a detailed guide on converting Pandas to Dictionaries using numerous examples.
How to Convert Pandas DataFrame to Python Dictionary?
To convert/transform a particular Pandas DataFrame to Dictionary, the “DataFrame.to_dict()” method is used in Python. The “DataFrame.to_dict()” syntax is shown below:
Here in the above syntax:
- The “orient” parameter specifies the type of value of the dictionary. It can be one of the following strings: “dict”, “list”, “series”, “split”, “tight”, “records”, or “index”.
- The “into” parameter specifies the “collections.abc.Mapping” subclass utilized for all mappings in the retrieved value. (Default is “dict”).
- The “index” parameter determines whether to add the index element to the returned dictionary.
The “DataFrame.to_dict()” method will return a dictionary with the column names as keys and the column values as sub-dictionaries with the index labels as keys.
Example 1: Convert Pandas DataFrame to Dictionary
This example uses the “df.to_dict()” method to convert Pandas DataFrame to Dictionary in Python:
dict1 = {‘name’: [‘Joseph’, ‘Anna’, ‘Lily’], ‘id’: [12, 22, 33], ‘salary’: [‘$334’, ‘$348’, ‘$583’]}
df = pandas.DataFrame(dict1)
print(‘DataFrame:\n‘, df)
print(‘\nDictionary Value:\n‘, df.to_dict())
In the above code:
- The “pandas” module is imported.
- The “pd.DataFrame()” creates the DataFrame by accepting the dictionary Data as an argument.
- The “df.to_dict()” method converts the Pandas DataFrame to Dictionary.
Output
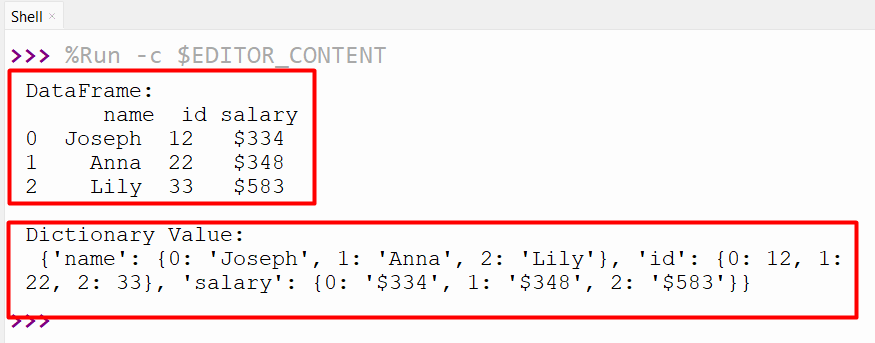
The dictionary has been created from the Pandas DataFrame.
Example 2: Convert Pandas DataFrame to Dictionary Using “orient” Parameter
This example code is used to convert DataFrame to Dictionary using the specified “orient” parameter value such as list or split:
dict1 = {‘name’: [‘Joseph’, ‘Anna’, ‘Lily’], ‘id’: [12, 22, 33], ‘salary’: [‘$334’, ‘$348’, ‘$583’]}
df = pandas.DataFrame(dict1)
print(‘DataFrame:\n‘, df)
print(‘\nDictionary Value:\n‘, df.to_dict(orient=‘list’))
In the above code, the “orient” parameter value “list” is passed to the “df.to_dict()” method to convert the Pandas DataFrame to the dictionary in the “list” orientation structure.
Output
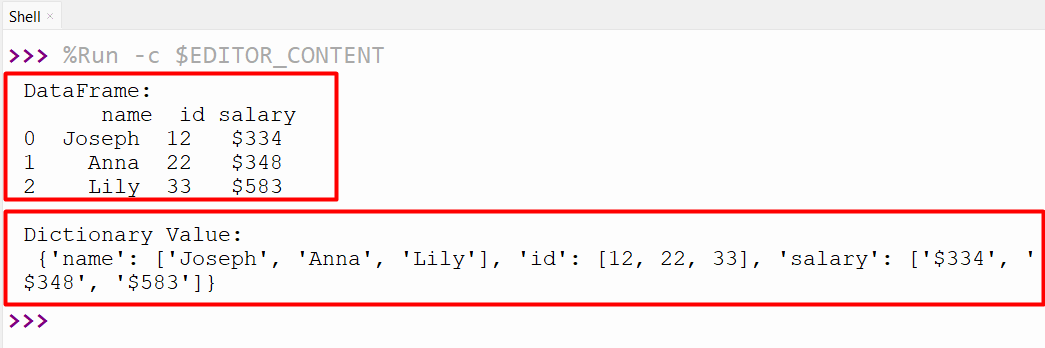
The dictionary has been returned in the “list” orientation.
Conclusion
In Python, the “DataFrame.to_dict()” method of the “pandas” module is used to convert the specified Pandas DataFrame to Dictionary. The “DataFrame.to_dict()” method takes the “orient” parameter as an argument and returns the DataFrame in a specified orientation such as “list”, “split”, etc. This article presented/delivered an extensive guide on Pandas to Dictionaries utilizing numerous examples.
Source: linuxhint.com