Pandas insert() Column
The “pandas” library in Python supports various modules and methods for handling and organizing data. While organizing or manipulating data, sometimes we need to perform various operations such as adding, removing, appending, and others on data. To add/insert a specified column to the Pandas DataFrame, the “df.insert()” method of the “pandas” module is used in Python.
This Python write-up will discuss about:
- What is the “DataFrame.insert()” Method in Python?
- Adding Column With Default Value Utilizing “df.insert()” Method
- Adding Column With Different Value For Each Row Using “df.insert()” Method
- Adding Duplicate Column to DataFrame Using the “df.insert()” Method
What is the “DataFrame.insert()” Method in Python?
The “DataFrame.insert()” method of the “pandas” module is used to add the same or different column value to the particular location. The syntax of this method is shown below:
In the above syntax:
- The “loc” parameter specifies the index value of the DataFrame where the column needs to be added.
- The “column” parameter represents the label name of the added column.
- The “value” parameter indicates the column value of the newly added column.
- The “allow_duplicates=” parameter indicates whether the added column value allows duplicates or not.
Return Value
The “DataFrame.insert()” method retrieves a new DataFrame with a column value added.
Example 1: Adding Column With Default Value Utilizing “df.insert()” Method
The below code is used to add/insert a column with default value:
df = pandas.DataFrame({'Name': ['Joseph', 'Anna', 'Lily', 'Henry'], 'Age': [14, 17, 19, 23],'Salary': [3200, 5400, 3200, 6600]})
print(df, '\n')
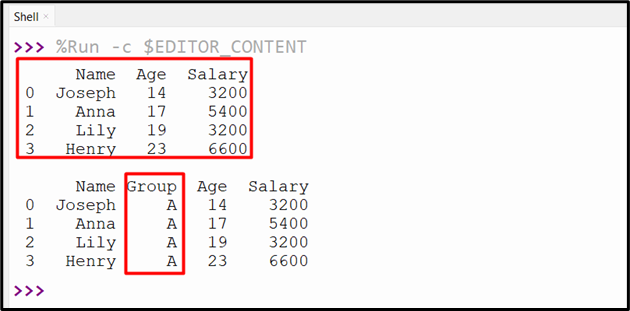
df.insert(1, "Group", "A")
print(df)
Here:
- First, add the “pandas” module and then create the “DataFrame”.
- Next, use the “df.insert()” method that takes the location/index, column label, and column value as an argument and adds/inserts the column with a default value to DataFrame.
According to the following output, the specified column with default value has been added to DataFrame:
Example 2: Adding Column With Different Value For Each Row Using “df.insert()” Method
This method can be used to add columns with different values for each row of Pandas DataFrame:
df = pandas.DataFrame({'Name': ['Joseph', 'Anna', 'Lily', 'Henry'], 'Age': [14, 17, 19, 23],'Salary': [3200, 5400, 3200, 6600]})
print(df, '\n')
list_A = ['A', 'B', 'A', 'B']
df.insert(1, "Group", list_A)
print(df)
In the above-given code:
- Used similar DataFrame values that are described in the previous example. Then, initialized the list containing multiple DataFrame column values.
- Next, invoked the “df.insert()” method and passed it the index location, column label, and the column value list as an argument and also added the specified columns to the Pandas DataFrame.
Output
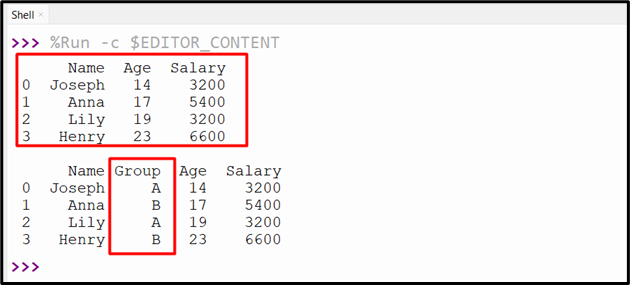
The columns with various values are added to the DataFrame.
Example 3: Adding Duplicate Column to DataFrame Using the “df.insert()” Method
The “allow_duplicates=” parameter of the “df.insert()” method is used to add the duplicates column to the DataFrame. Here is a code of how we can accomplish/achieve this:
df = pandas.DataFrame({'Name': ['Joseph', 'Anna', 'Lily', 'Henry'], 'Age': [14, 17, 19, 23],'Salary': [3200, 5400, 3200, 6600]})
print(df, '\n')
list_A = [15, 23, 33, 45]
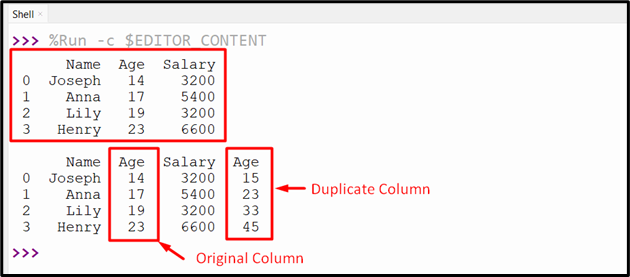
df.insert(3, "Age", list_A, allow_duplicates=True)
print(df)
In the above code:
- The starting code is the same as the previous one. Then, use the “df.insert()” method that takes the additional “allow_duplicates=True” parameter as an argument to add the same existing column “Age” with new values to the DataFrame.
It can be seen that the DataFrame duplicate column has been added to the DataFrame:
Bonus Tip: Add the Column to Pandas DataFrame Using the “df.assign()” Method
The “df.assign()” method is used to add a single column to the end of the Pandas DataFrame. Here is an example of adding the column to DataFrame:
df = pandas.DataFrame({'Name': ['Joseph', 'Anna', 'Lily', 'Henry'], 'Age': [14, 17, 19, 23],'Salary': [3200, 5400, 3200, 6600]})
print(df, '\n')
df = df.assign(Height=[12, 22, 14, 27])
print(df)
Here, use the “df.assign()” method that takes the column name with various values as an argument and adds the column to the end of the Pandas DataFrame.
Output
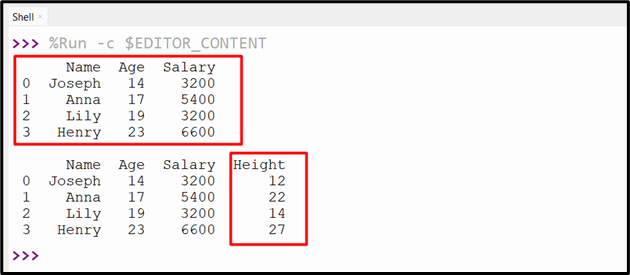
The specified column has been inserted into DataFrame.
Conclusion
The “DataFrame.insert()” method is utilized to add/insert the column with a default value or a different value to Pandas DataFrame. This method provides an “allow_duplicates=” parameter to add duplicate columns to DataFrame. The other methods, such as “df.assign()”, can also be used to add a column to Pandas DataFrame. This write-up illustrated a detailed guide on the “pandas.insert()” method utilizing numerous examples.
Source: linuxhint.com