Pandas Fuzzy Match
How to Perform Fuzzy Matching in Pandas?
Different functions and properties can be used to perform fuzzy matches on the columns of pandas dataframe in python. We will demonstrate a few of them in the examples below.
Example 01: A Basic Approach to Performing Fuzzy Matches in Pandas
First, we will import the fuzzywuzzy libraries along with the pandas library. The fuzzywuzzy package has several useful functions, such as the ability to determine the Levenshtein distance, which can be useful in fuzzy string matching. Now, let’s create two dictionaries. After creating lists, we will also create two empty lists to store the matches later as seen below.
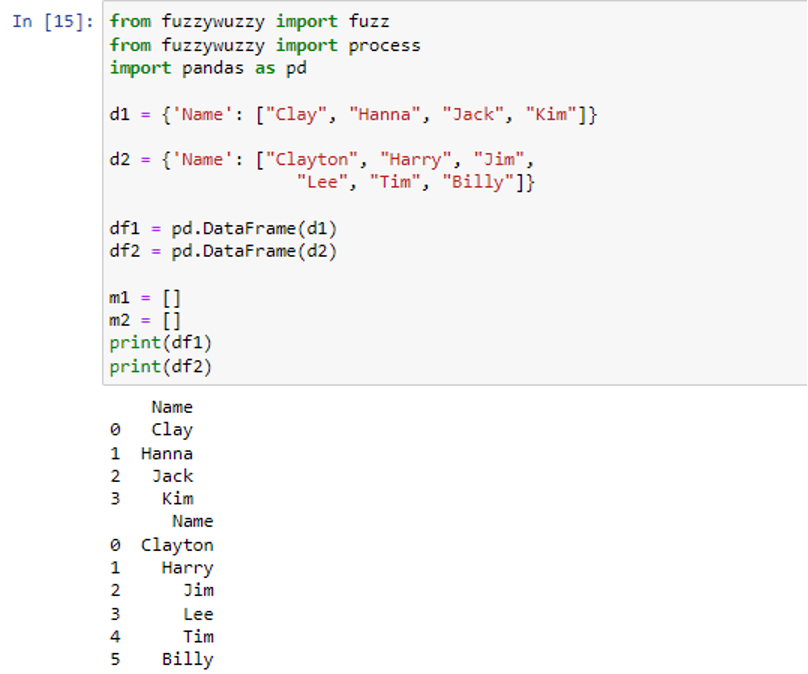
The dictionaries are passed inside the pd.DataFrame() function to create dataframes ‘df1’ and ‘df2’ with the single columns ‘Name’ with values (‘Clay’, ‘Hanna’, ‘Jack’, ‘Kim’) and (‘Clayton’, ‘Harry’, ‘Jim’, ‘Lee’, ‘Tim’, ‘Billy’) respectively. The dataframes will now be transformed into lists using the tolist() function. We will set the threshold to 75 so that the matching only starts when there is 75% similarity between both strings.
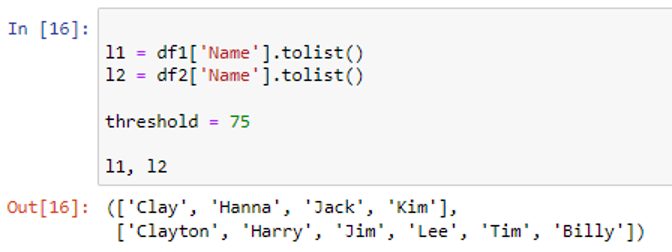
It can be seen that our dataframes are converted to lists. To find the optimal match from the list2, we will repeatedly iterate through the list1’s items. Here, we extract the elements using the processing module’s “process.extract()” function. If we print it now, we can see the accuracy ratio numbers since “Limit=2” instructs it to only retrieve the two closest items with their accuracy ratio. To the list m1, we will add each closest match. In the dataframe, ‘df1’ list of matches will be stored in the “match” column.
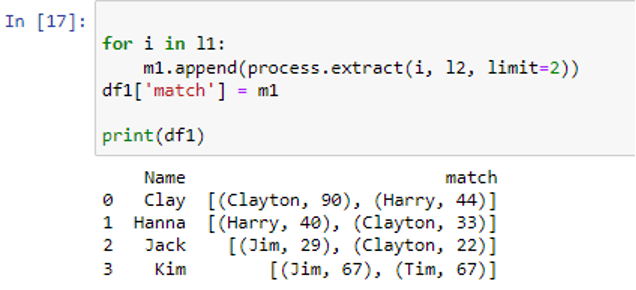
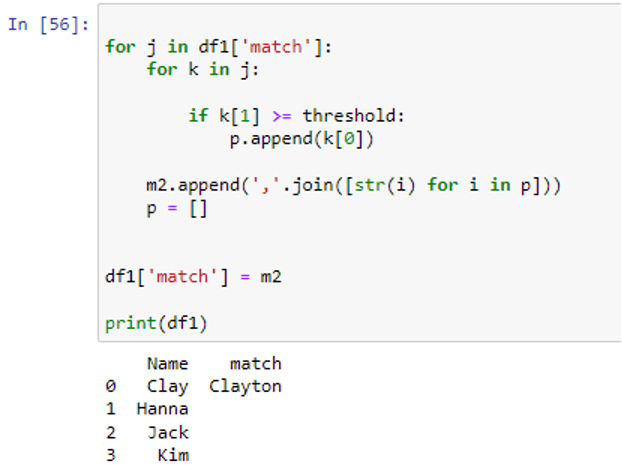
The outer loop will once more run through the “match” column and the inner loop will iterate through each group of matches. If k[1] >= threshold, only items with threshold values equal to or more than 75 will be selected and added to the list “p”. If there are multiple matches for a given column item, the item matches will be joined using the “,”.join() function and appended to list m2. To store the matched output of the following item of rows in the dataframe ‘df1’ column, the list ‘p’ will be set to empty. To obtain our final output, the closest matching will be stored to dataframe ‘df1’.
Example 02: Using the process.extractOne() Method to Perform Fuzzy Matching in Pandas
The process.extractOne() method will now be used to match just the closest values from the two dataframes. The various fuzzy matching functions will be used in this method. Process.extractOne (query, scorer, choice) extracts the single match that most closely fits the supplied query from the choice list. Scorer is an optional parameter that can be used to specify a specific scorer, such as fuzz.token_sort_ratio or fuzz.token_set_ratio. Like in example 1, we will create two lists and then convert them into dataframe columns.
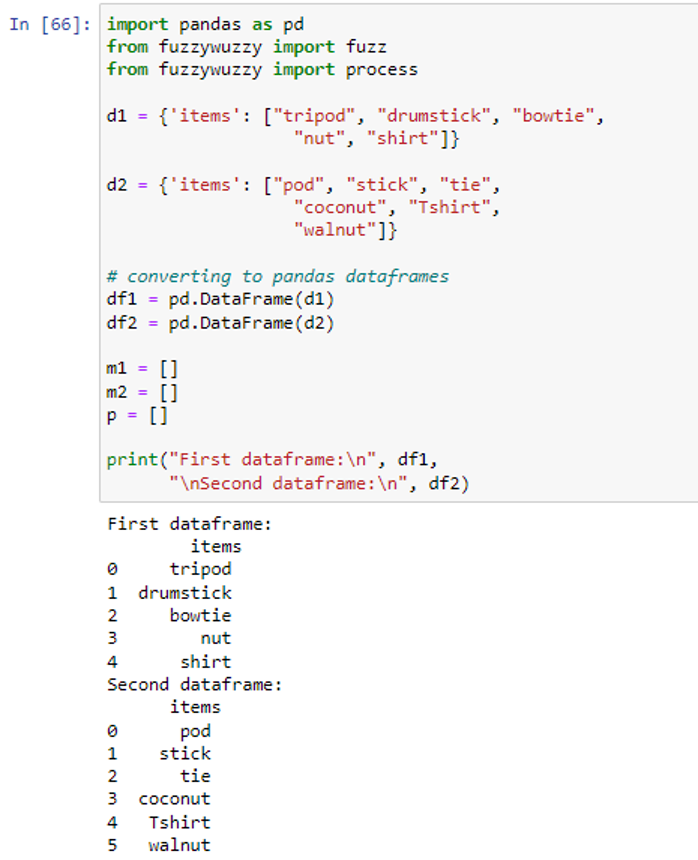
First, we imported the pandas and fuzzywuzzy modules. Then, we created two python dictionaries ‘d1’ and ‘d2’. The keys of both dictionaries are ‘items’ and the values of d1 and d2 are (“tripod”, “drumstick”, “bowtie”, “nut”, “shirt”) and (“pod”, “stick”, “tie”,”coconut”, “Tshirt”, “walnut”). We have created the dataframes ‘df1’ and ‘df2’ by passing the dictionaries d1 and d2 in the pd.DataFrame() function. The three empty lists ‘m1’, ‘m2’, and ‘p’ are also created which we will use later to store the matching values.
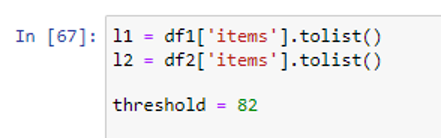
The dataframes df1 and df2 are converted to lists l1 and l2 using the tolist() function so we can iterate through them to find the matches. We will iterate through list l1 to extract its closest match from list l2. The threshold value is specified as 82 so, the fuzzy matching only takes place only when strings will be at least 82 percent close to one another.
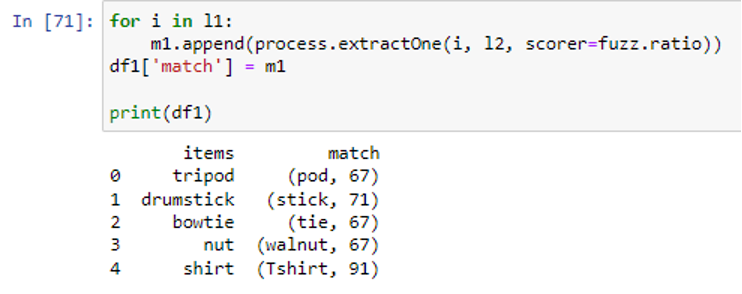
The scorer parameter is specified as fuzz.ratio to determine the ratio of resemblance between two strings depending on the Levenshtein distance. To filter out the maximum closest match, each group of matches will now be iterated through by the loop. Only those items will be selected and appended to list “p” that satisfies the condition j[1] >= threshold which is greater than 82. If more than one match is found for a particular column item, the matches are merged using the “,”.join() method and added to list m2. The list “p” will once again be set to empty to hold the output of the matching items in the dataframe “df1” column. The output match values will be stored back to ‘df1’ in the column ‘match’.
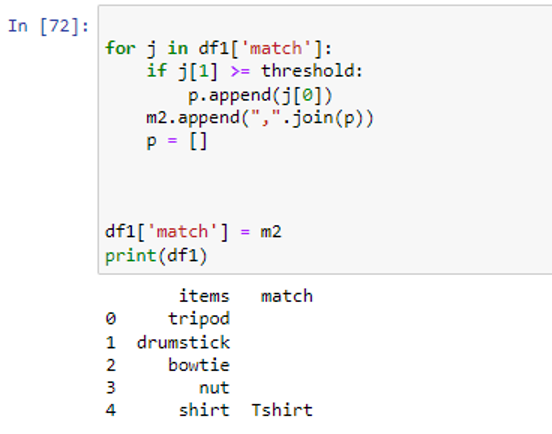
There is only one match where the similarity ratio is more than 82%. If we reduce the threshold, we may get more matching values in the ‘match’ column of ‘df1’
Example 03: Using the get_close_matches() Method to Perform Fuzzy Matching in Pandas
Using the get_close_matches() method from the difflib package is one of the simplest ways to execute fuzzy matching in Pandas. Let’s create our dataframes first by using the pd.DataFrame() function.
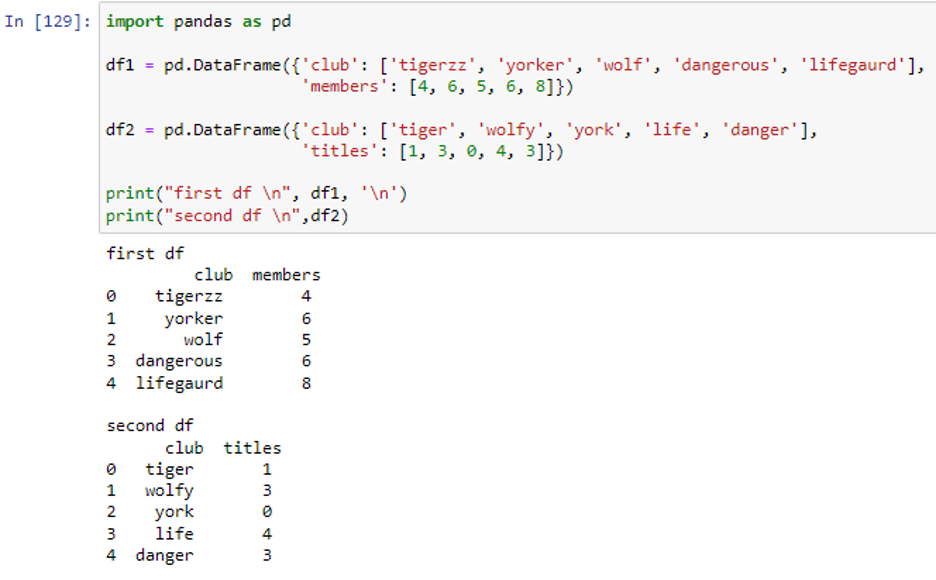
We have created two dataframes ‘df1’ and ‘df2’. The dataframe df1 consists of 2 two columns “club” with values (‘tigerzz’, ‘yorker’, ‘wolf’, ‘dangerous’, ‘lifegaurd’) and “members” having values (4, 6, 5, 6, 8). There are also 2 columns in ‘df2’ with labels “club” and “titles” having values (‘tiger’, ‘wolfy’, ‘york’, ‘life’, ‘danger’) and (1, 3, 0, 4, 3) respectively. Let’s say we want to combine our dataframes based on the “club” column. We will use the fuzzy match technique to determine which club names are the closest matches because the club names in the two DataFrames differ slightly from one another. To accomplish this, we can use the get_close_matches() method from the difflib package. First, we will import the difflib module.
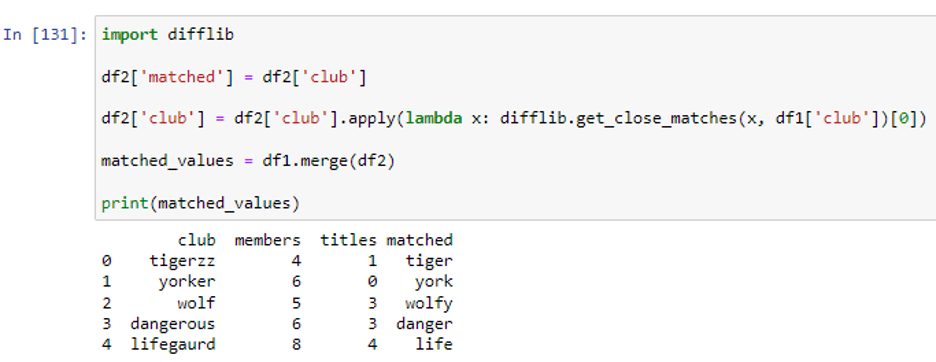
We have created a duplicate column “matched” to retain values of column club from df2. Then, we converted the ‘club’ column values in dataframe ‘df2’ to club values it closest matches in dataframe ‘df1’ using the get_close_matches() method inside the apply() function. In the last step, we merged our dataframes ‘df1’ and ‘df2’ to create a new dataframe ‘mached_values’. It can be noticed that the column ‘matched’ in the above dataframe contains the values which are most closely matched with the corresponding values in the ‘club’ column.
Conclusion
In this tutorial, we teach how you can perform fuzzy matching in pandas. We have discussed the fuzzywuzzy library and how it helps us in the matching of strings. We implemented 3 examples in this tutorial. In the first example, we showed the basic approach to performing a fuzzy match with pandas dataframes. In the second example, we used the process.extractOne() method to extract the fuzzy matches.
Source: linuxhint.com