Pandas Frequency Count
A popular Python library named “Pandas” can provide/support numerous data analysis modules and methods. While working with data in DataFrame, it is sometimes necessary to calculate how often a specific value occurs in a specific column. To determine the frequency count for the specified value, various methods are used in Python.
This article presents a detailed guide on counting the frequency value in specified columns using the below methods:
- Using “values_count()” Method
- Using “size()” Method
- Using “count()” Method
- Using “crosstab()” Method
Method 1: Count the Frequency of Value in Specified Column Using “Series.values_count()” Method
The “Series.values_count()” method retrieves the series object that contains a unique value count. This method counts the frequency of the specified Pandas DataFrame column. For a better understanding, take a look at this example:
Example 1: Frequency Count of Single Column
Here is an example of counting the frequency of a specified single column:
df = pandas.DataFrame({'Name':['Anna', 'Lily', 'Anna', 'Joseph', 'Lily', 'Anna', 'David'],'Points':[1, 2, 3, 1, 2, 5, 6],'Country':['USA', 'England', 'China','Germany', 'USA', 'USA','England']})
print(df, '\n')
df1=df['Name'].value_counts()
print(df1)
In the above code:
- The “pandas” library is imported.
- The “pandas.DataFrame()” is created with columns having multiple duplicates.
- The “values_count()” method counts the frequency of the specified column “Name”.
Output
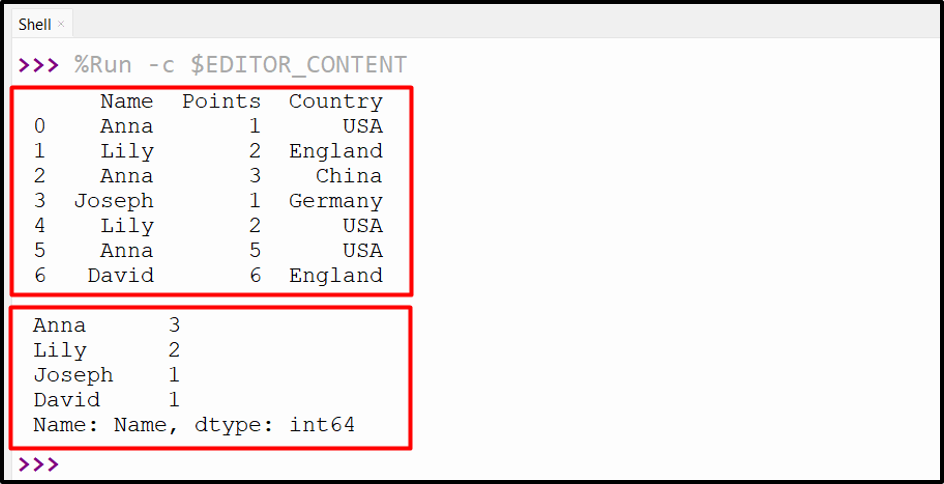
The frequency value of the column “Name” has been calculated successfully.
Example 2: Frequency Count of Multiple Columns
Let’s utilize the below code for multiple columns:
df = pandas.DataFrame({'Name':['Anna', 'Lily', 'Anna', 'Joseph', 'Lily', 'Anna', 'David'],'Points':[1, 2, 3, 1, 2, 5, 6],'Country':['USA', 'England', 'China','Germany', 'USA', 'USA','England']})
print(df, '\n')
df1=df[['Name', 'Country']].value_counts()
print(df1)
In the above code:
- The “value_counts()” method is used to count the frequency of the multiple columns named “Name” and “Country”.
Output
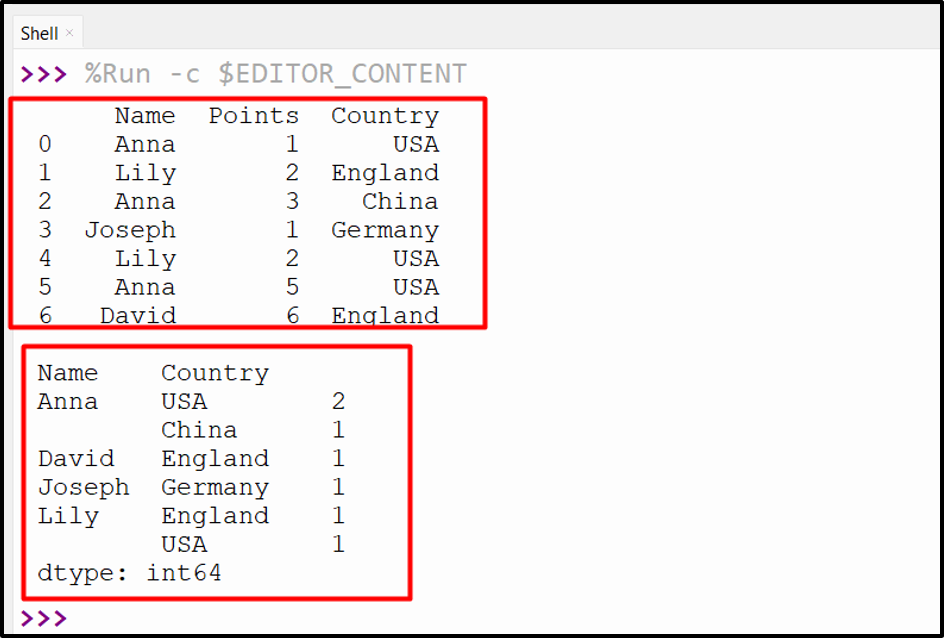
From the above output, we can verify that the frequency values of multiple columns have been calculated successfully.
Method 2: Count the Frequency of Value in Specified Column Using “GroupBy.size()” Method
The “GroupBy.size()” method can also be utilized to count the frequency value of the DataFrame column. This method is used to group the specific columns using the “df.group()” method and apply the “size()” method to count the frequency value. For example, take the below code:
df = pandas.DataFrame({'Name':['Anna', 'Lily', 'Anna', 'Joseph', 'Lily', 'Anna', 'David'],'Points':[1, 2, 3, 1, 2, 5, 6],'Country':['USA', 'England', 'China','Germany', 'USA', 'USA','England']})
print(df, '\n')
df1=df.groupby(['Name']).size()
print(df1)
Here in this code:
- The “groupby()” method is used to group the Pandas DataFrame according to the particular column “Name”.
- The “size()” method is used along with the dot notation syntax to count the frequency value of that specific column.
Output
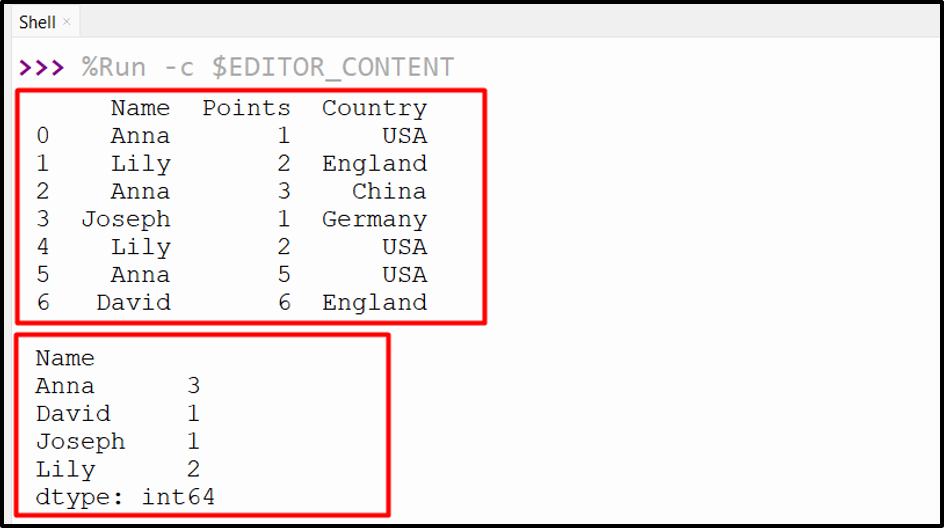
The frequency/count of each name has been shown in the above output.
Method 3: Count the Frequency of Value in Specified Column Using “GroupBy.count()” Method
The “df.groupby()” method can be combined with the “count()” method to find the frequency count of the specified DataFrame column. Here is an example:
df = pandas.DataFrame({'Name':['Anna', 'Lily', 'Anna', 'Joseph', 'Lily', 'Anna', 'David'],'Points':[1, 2, 3, 1, 2, 5, 6]})
print(df, '\n')
df1=df.groupby(['Name']).count()
print(df1)
In the above code:
- The “df.group()” method takes the “Name” column as an argument and groups the data based on the given column.
- After that, the “count()” method counts the frequency value of the specified column.
Output
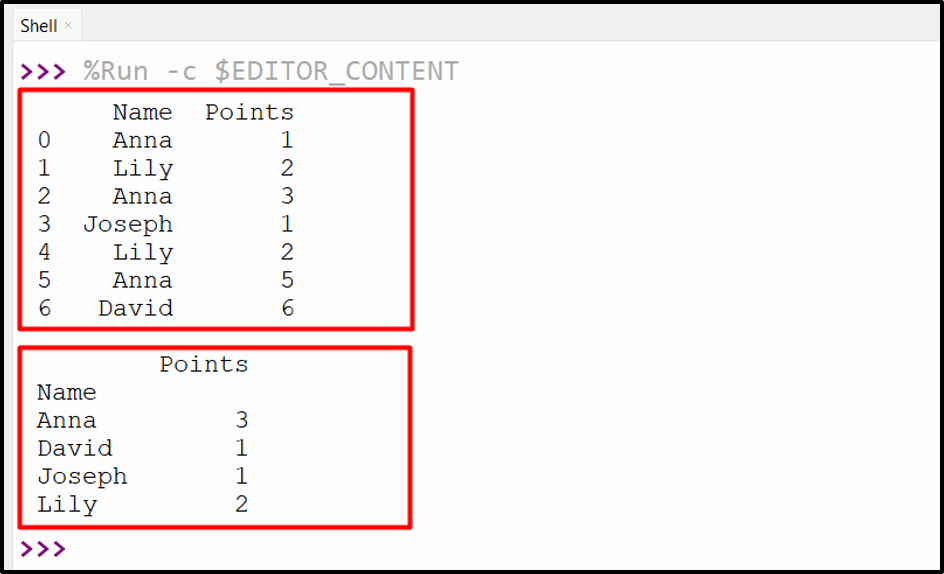
The frequency count of the specified column has been determined.
Method 4: Count the Frequency of Value in Specified Column Using “pandas.crosstab()” Method
The “pandas.crosstab()” method is used to determine the simple cross-tabulation of two or multiple factors. This particular method can also be employed to count the frequency value of the specified columns. Here is an example:
df = pandas.DataFrame({'Name':['Anna', 'Lily', 'Anna', 'Joseph', 'Lily', 'Anna', 'David'],'Points':[1, 2, 3, 1, 2, 5, 6]})
print(df, '\n')
df1=pandas.crosstab(index=df['Name'], columns='frequency')
print(df1)
In the above code:
- The “crosstab()” method takes the column “Name” and calculates/retrieves the frequency of data to the new column “frequency”.
Output
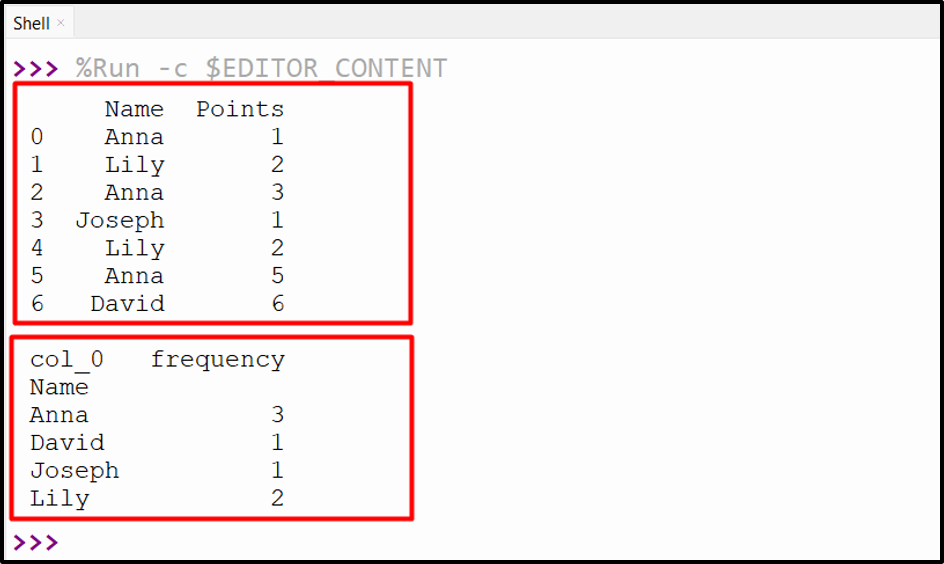
The frequency of the specified column has been calculated successfully.
Conclusion
The “Series.values_count()”, “GroupBy.size()”, “GroupBy.count()”, and “pandas.crosstab()” methods calculate the frequency count of the specified column. The “values_count()” method can determine the frequency count of the single or multiple columns. The “groupby()” method can also be used with the “size()” or “count()” method to determine the frequency count of the specified column. This article has delivered a detailed guide on counting the frequency value of a specified column.
Source: linuxhint.com