Pandas Combine DataFrames
How to Combine DataFrames in Pandas
Several methods can be used to combine two or more DataFrames. We will discuss some of them in the following examples.
Example 1: Combining Two Pandas DataFrames Using the Merge() Function
We start this example by creating two simple DataFrames and naming them “df1” and “df2”. To create the DataFrames, we have to import the Pandas module first to use its functionalities. The pd.Dataframe is used to create our DataFrames.
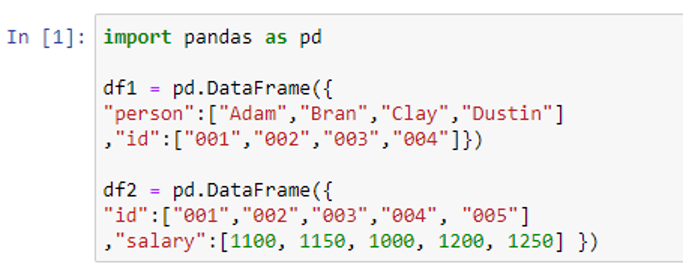
To create our DataFrames, we pass the dictionaries inside the pd.DataFrame() and assign the DataFrames to the “df1” and “df2” variables.
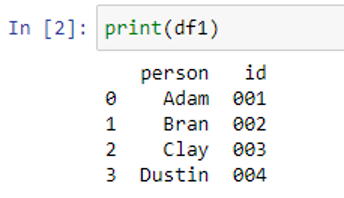
In our DataFrame “df1”, we have two columns – “person” and “id” – that store the names of persons and id numbers of those persons, respectively.
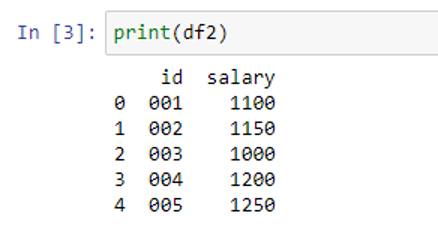
In our second DataFrame “df2”, there are also two columns – “id” and “salary” – that store the dummy id numbers and salaries of individuals. Let’s use the merge() function to join these DataFrames. Take a quick look at all the options that this method can accept before continuing:
Syntax

Except for the parameters right and left, the majority of these parameters have default values. The DataFrames names that we combine are contained in these two parameters. A new DataFrame is returned by the function itself, which we save in the “merge_df” variable.

Because the column id in both DataFrames “df1” and “df2” has the same label, the merge() method automatically combines the two DataFrames based on that key. We specify the parameters left_on=”name of left column” and right_on=”name of right column” to specify the keys explicitly for our DataFrames if there is no column with the same column name in both DataFrames. Let’s print our new combined DataFrame with the print() function.
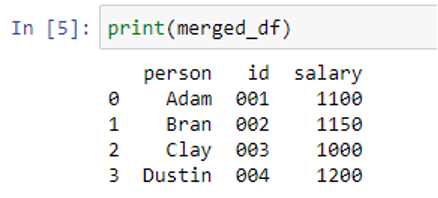
As you can see, merged df contains just 4 rows while df2’s original contains 5 rows. This is because a new DataFrame is created by intersecting the right and left DataFrames when the “how” parameter’s default value is set to “inner” inside the pd.merge() function. Therefore, the combined DataFrame would not contain an id that is missing from one of the tables.
If the right and left rows were switched over, this is still true:

The output is the same.
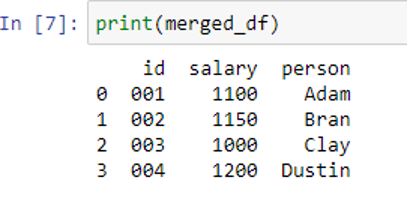
But the ID “005” is still not a part of the combined DataFrames. Even though none of the rows intersect, there could be situations when we want to include the data of both DataFrames in the merged DataFrame containing all of its rows.
We can set the “how” parameter to “right” inside the merge() function.
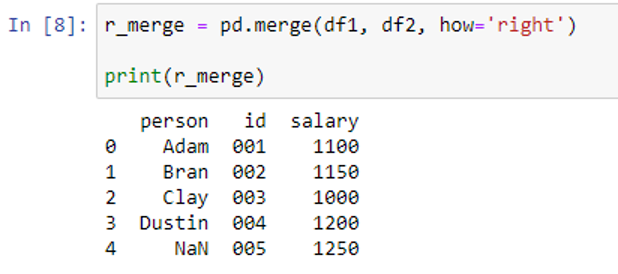
The function includes every element of the right DataFrame “df2” and left DataFrame “df1” using a right join. If the rows were missing from DataFrame“df1”, we use the how=’left’.
Example 2: Combining Two Pandas DataFrames Using the Join() Function
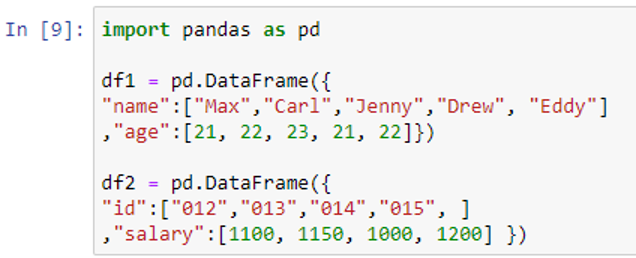
Join() is a function of the DataFrame itself, as opposed to merge(), which is a function of the Pandas instance. It can therefore be used on the DataFrame like a static method. Let’s first create two sample DataFrames df1 and df2 so we can combine or merge them by using the join() function.
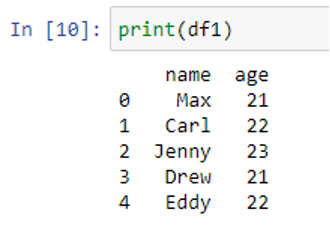
To see the content of both DataFrames, let’s print them one by one.
Now, print the second DataFrame “df2”.
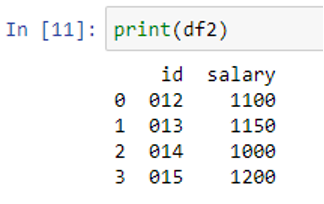
Since we created our DataFrames, look at the syntax of the join() function:
Syntax

Our left DataFrame “df1” is the one on which we call the join() function. Our right DataFrame “df2” is the one in the “other” parameter inside the join() function. The “how” parameter accepts one of the handling parameters (left, right, outer, or inner) whereas the “is” parameter by default is set to left. The “on” parameter can accept one or more arguments (list of keys) to specify the matching key.
Now, we join df2 with df1.
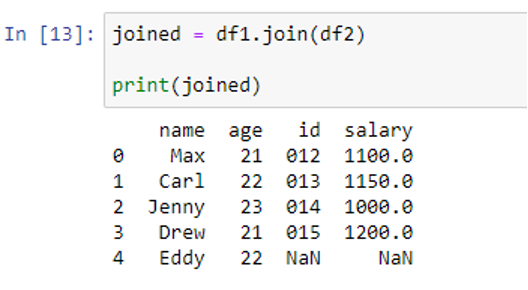
As can be seen, we have DataFrames “df1” and “df2” using the join() function. The output of the join() function can be modified by using the different parameters and specifying the different arguments for them.
Example 3: Combining Two Pandas DataFrames Using the Concat() Function
Compared to merge() and join(), concatenation is a little more flexible because it enables us to merge the DataFrames either horizontally (column-wise) or vertically (row-wise). The major drawback is that the data is eliminated or discarded if the column labels don’t match or do not exist in both DataFrames. The function’s syntax is as follows:
Syntax

Parameters
- objs: The list of DataFrame objects ([DataFrame1, DataFrame2,…]) that will be concatenated.
- axis: It determines the order of the concatenation, column-wise if specified to 1 and row-wise if specified to 0.
- join: It can be specified as “outer” for union and “inner” for the intersection.
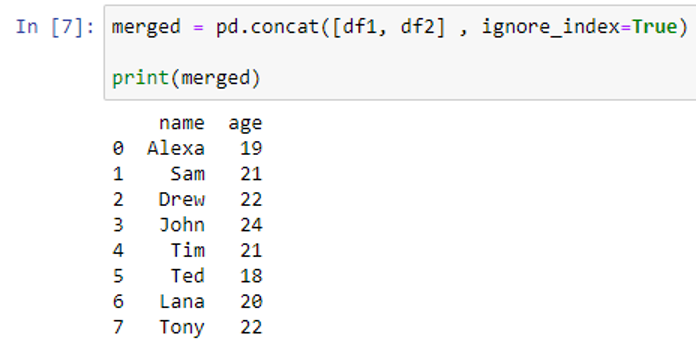
- ignore_index: It can result in duplicate index values because “ignore index” is by default False, which keeps the index values the original DataFrames. If True, it re-assigns the index in sequential order while ignoring the original values.
- keys: We can create a hierarchical index using keys. Consider it as an additional level of the outer-left index that helps in the identification of indexes when duplicating. Now, let’s create our DataFrame having the same column labels and datatypes.
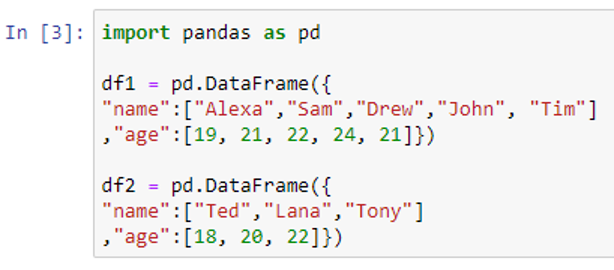
Let’s print our DataFrames “df1” and “df2” to see their contents.
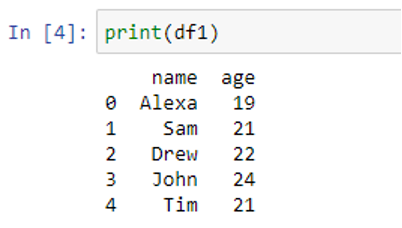
We have two columns in “df1”. Now, “df2” must have two columns with the same names.
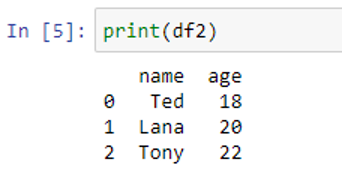
The DataFrame “df2” also consists of “name” and “age” columns having the same datatypes as the “df1” DataFrame’s columns.
Now, we pass the df1 and df2 in the objs parameter as a list ([df1, df2]) to combine them row-wise. And then, we assign the new merged DataFrame to the “merged” variable.
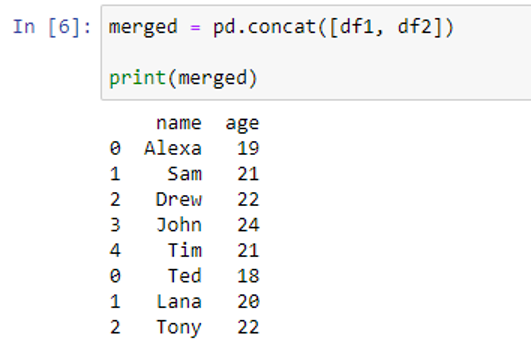
As can be seen, the data of “df2” is row-wise merged with “df1”. However, notice the indexes on the left side of each row. The numbers 0, 1, and 2 keep repeating. We set the ignore_index argument to True to obtain the distinct index values.
The axis value must be changed from the default value of 0 to 1 to combine the “df1” and “df2” column-wise.
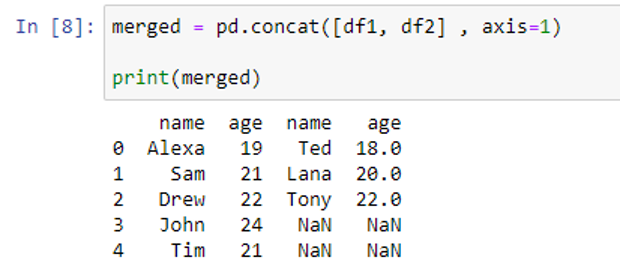
You’ll observe that it differs from merge() which matches two DataFrames on a key.
There are also other methods in Pandas like append() and combine_first() and update() to combine two DataFrames.
Conclusion
In this tutorial, we have seen that combining the DataFrames allows us to both create a DataFrame by changing the original data source and generate a new DataFrame without changing the data source. We have seen the syntax of functions used for merging the DataFrames. We tried to teach you how you can combine two Pandas DataFrames using the join(), merge(), and concat() functions. Now, you may be able to combine the DataFrame() and assign the DataFrame by yourself using these functions.
Source: linuxhint.com