MongoDB Group by Multiple Fields
“MongoDB database plays an important role in data storing and manipulating. To organize data, we create groups to gather the same sort of data in one place. Grouping can be on different attributes, whether from the count variable or any other feature. This tutorial will explain the group creation according to different fields of documents.
For the implementation of the phenomenon of groups according to multiple fields, we need to have some data in the database. We will create a database first. This is done by declaring the name of the database with the keyword “use.” For this implementation, we are using a database “demo.”
Once you are done with the database creation, data will be inserted into the database. And for the data entry we used to create “collections,” these are the containers that play an important role in storing limitless data in them. At a time, we can create many collections in a single database. Here we will create a database with the name “info.”
The response of MongoDB will be, “ok”; it is the confirmation of the creation of the collection. The data in the collection is entered row by row. So we will insert data into the collection. As this data will be used further in examples to create groups according to different fields, so we have entered many rows. Each time a different id is assigned to each row.
"Age" : 28,
"Gender" : "Male",
"Country": "United States of America"})
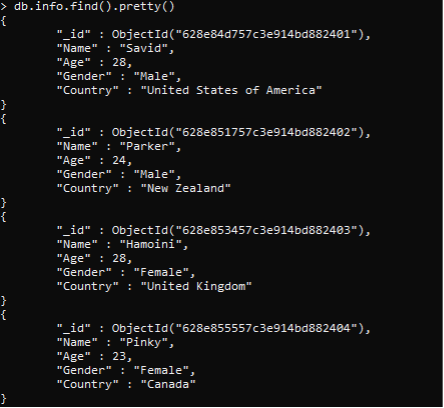
Similarly, all the data will be inserted. You can see all inserted data by using the find() command
Example 1: Group by Multiple Fields/Attributes
When we have a large set of data in the database, but we want to take a view of a few of them, then for this purpose, $groups are found. In this example, we will create a group to see some particular attributes from the collection. The group factor relies on the aggregate operation. An aggregate operation is used, to sum up the data according to the common fields. The Dollar “$” sign denotes the variable. Now apply a query on the above info collection.
A group depending on id, will be created. And then, only the age and gender documents are selected to be displayed. Whereas the entire data, including the name and country, are removed. This is somehow a filter that is used to limit the display of data.
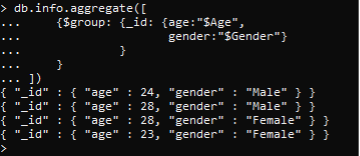
You can see that we have grouped each row according to id by limiting the data to two attributes.
Example 2: Group Through Multiple Fields by Applying a Condition
This refers to the grouping of the documents according to a specific condition. A group will be created on two attributes, and after the group creation, we will add a count variable to count the occurrence of the value of a specific document. And also, we have added a sorting order.
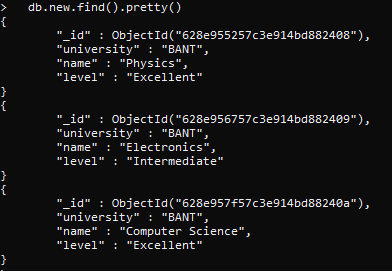
First, let us display the documents in our collection “new.” We have created a collection and added data to it earlier by following the same steps described above. We will only display all the items in the collection through the find() function.
The query will contain the group part first. The group is created on id; university and level are the two basic attributes that we want to get displayed. The variable we use gets the value from the collection and then assigns it to the query variable. All the values and conditions are not written directly in the command.
After the group creation, the condition is applied; it is to count and calculate the sum according to the levels of each document. After that, this answer will be arranged in descending order. This is done through the sort() functions. This function contains only two parameters; for the ascending value, it is 1, and for descending, it is -1.
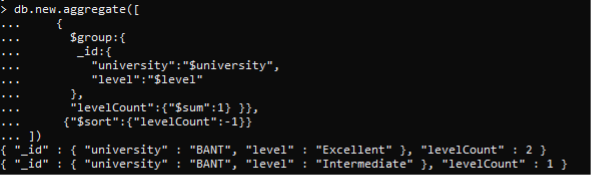
The descending order will show that the greater amount of the level will be displayed first, and then the smaller one is displayed following the level document.
Example 3: MongoDb BUCKET Group by Multiple Fields
As the name indicates that the groups are found according to the bucket. This is done by creating the bucket aggregation. Bucket aggregation is the process of categorizing the documents into groups. This group acts like buckets. Each document is divided depending on the specific expression.
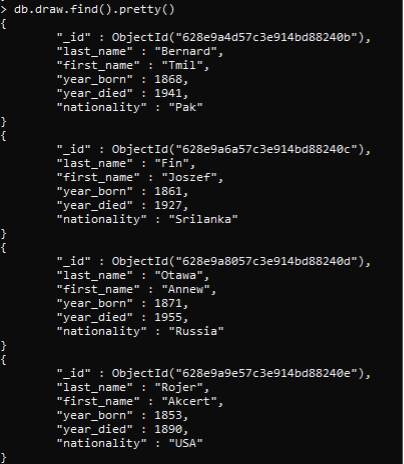
To elaborate on this concept, we will take a look at a collection we have created, and now we will apply the commands to that. A “draw” collection is created that stores the basic information regarding a person. We have displayed all the 4 rows entered into the collection earlier.
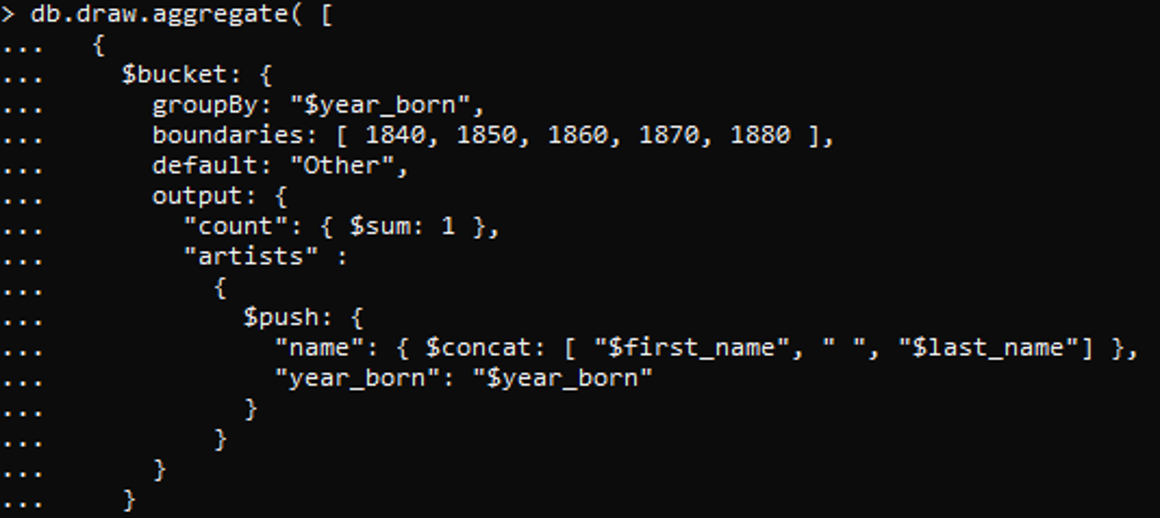
On the above data, we will apply a command to create a bucket (group) having the year as an attribute to group the data. We have also created boundaries in which the year of born and death are mentioned. The conditions applied on this command include the count variable to count the number of occurrences. We have also used a concatenation method here to combine both the first and the second names as strings. And also, the year of birth will be displayed. The id depends on the year.
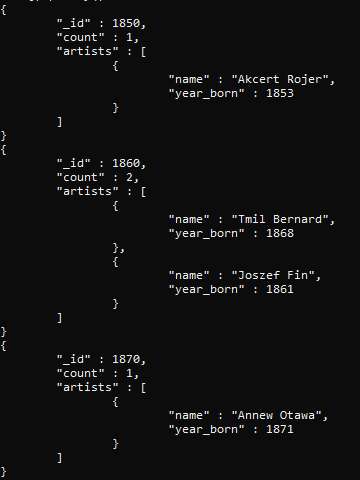
When we compute this query, the resultant value will show that two rows are grouped depending on the age boundaries we have created.
Conclusion
The MongoDB feature of grouping depending on more than a single field is elaborated in this article by demonstrating the working of the aggregate operation in group creation. Any group function is incomplete without the aggregate feature. The group feature is applied directly through the different fields to limit the exposure of entire data. The grouping via multiple fields is also accomplished by applying a particular condition. In the end, we have described the creation of a bucket group that contains more items like a bucket.
Source: linuxhint.com