MongoDB Find Duplicates
It came up with the aggregate function to find out the duplicate values from the collection. Within this article today, we will be discussing the insertion of duplicate records within the Mongo DB collections and display them on the MongoDB shell using the aggregate command of collections. Let’s start with our today’s article by the use of apt update and upgrade instructions within the terminal shell of the Ubuntu 20.04 system. For that, you need to log in first and open the shell by the use of “Ctrl+Alt+T.” After that, you can try the shown-below instruction at your shell and add the password for the user to continue the update process.”

It might require your confirmation to continue this process. Tap “y” upon asking: “Do you want to continue?”. After that, hit the Enter key.

It may take more or less time to process according to the situation of your system.
![]()
After the complete update, you will get the shown-below last lines of processing.

After the successful system update and upgrade, we have to open the MongoDB shell to insert some collections and records within the database. So, we have been using the “mongo” query to do so, as displayed in the image. The shell has been prepared successfully.
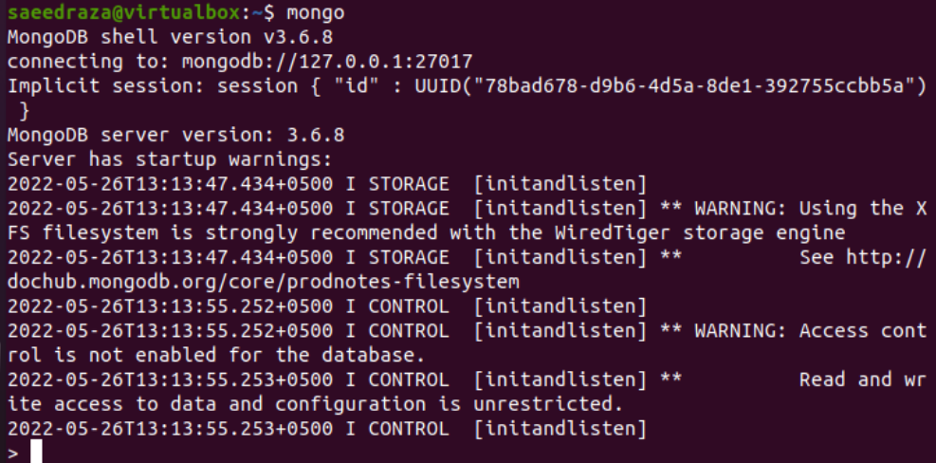
While using the “db” instruction at the MongoDB shell, we have found that the “test” database is available for our use.

Therefore, we have been using the “test” database for further queries and creating collection within it. For that, try the “use” instruction followed by the name of a database, i.e., “test.”

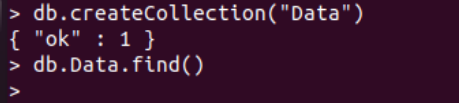
To add records, we need a collection in the test database. Thus, we need to create a new collection. For that, we have to try out the “db” instruction along with the “createCollection()” function of MongoDB, followed by the name of a new collection within its parenthesis, i.e., Data. The query was successful, and the collection was created successfully as per the status “ok: 1”. Moreover MongoDB, we tend to utilize the find() function preceded by the collection name to display the records of a specific collection. Therefore, we have tried the “db” instruction followed by the collection name, i.e., Data, and the function find() to do so. The collection “Data” is empty right now. Thus, we need to add some records to the collection.
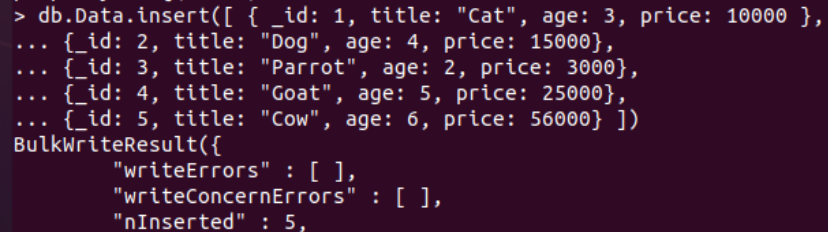
To insert the records within the Data collection of MongoDB, we need to try out the insert() function within the “db” instruction along with the data in the form of documents, i.e., list format. We have been using a total of 4 columns for the document data of collections, i.e., _id, title, age, and price. We have added a total of 5 records for all these 4 columns of Data collection.
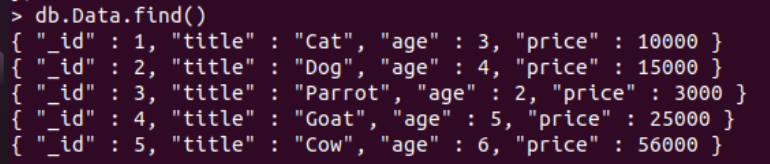
The record was added successfully as per the output above shows the number of records 5 for the “nInserted” option. After this, we will be using the find() function with the “Data” collection to find and display all the records of this collection. We are not passing any arguments to the parenthesis of a find() function to not restrict the collection records. All the 5 records for Data collection have been presented in the Mongo DB shell.
As we have been dealing with the topic of finding the duplicates in the collections of MongoDB, we must have some duplicate records in the collections as well. Therefore, we have been inserting three more records within the Data collection to be used as duplicates of some of the already inserted records. We need to update the “_id” column only as the ID of any column must be unique in MongoDB as we used to do in traditional databases. The same insert function has been used so far with the “Data” collection name. All three records have been added.

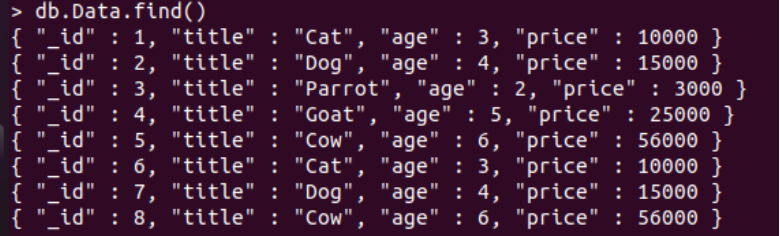
Now, when you run the “db” instruction with the collection name “Data” followed by the find() function once again on the MongoDB shell, the total of 8 records will be displayed on your screen. We can see the duplicate values for columns other than “_id” in this collection data.
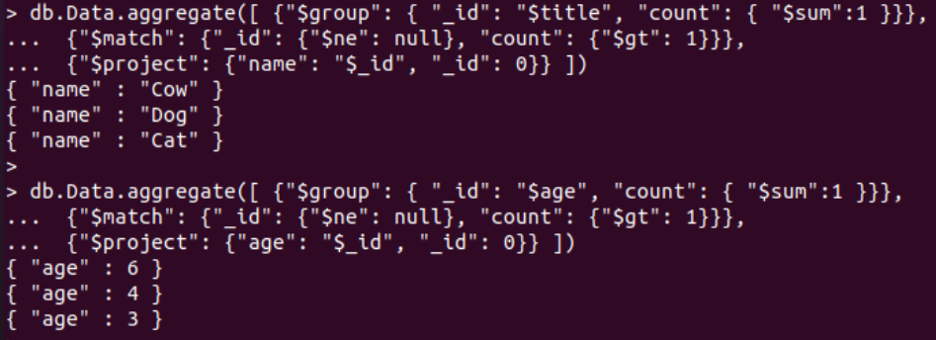
It’s time to try out the aggregate() method for the “Data” collection to list out the specific column values that are duplicated in it. You need to use the shown-below syntax of an aggregate command in MongoDB. The option “$group” is used to add all duplicate values of a specific column in one, while the option $match will be utilized to find out the groups having more than 1 document. On the other hand, the “$project” option will be used to specify the format of showing the duplicate records. The first field of the “$group” option will specify the column name in which we will be searching for duplicates. A total of 3 records have been found duplicated for the column “title” of a Data collection. After this, the same query was tried for the “age” column and got the 3 results again.
Conclusion
The explanation of duplicate records has been given in the introductory paragraph, and we have discussed the difference between finding out the duplicates from traditional databases and MongoDB. For this purpose, we have tried to give an illustration about making a new collection within MongoDB and inserting records within it. Moreover, we have discussed the use of the aggregate function to find out the specific column containing the duplicate value within the collections. This article has displayed the clear difference in finding out the duplicates for MongoDB as a comparison to any other database.
Source: linuxhint.com