How to Use MongoDB With Time-Series
“Insert, update, locate, delete, and aggregate are all operations that may be performed on a Time Series collection, just as they are on a standard collection. Behind the curtain, the fundamental difference exists. When you insert data into MongoDB, it is converted to an optimal storage format. A Time Series is simpler and more query-efficient than a regular collection.
Time Series collections are treated as non-materialized writable views in MongoDB. The data is saved more efficiently, conserving disc space, and a time-based internal index is built automatically. Instead of snappy, the zstd algorithm is used by default to compress the data. The new compression has a higher ratio, requires less CPU power, and is particularly well suited for time series analysis with minor differences between documents.
It is possible to change the compression algorithm in the future, although this is not encouraged. When you insert a document, a Time Series collection is not built automatically like other collections. It must be created expressly.”
What is Time-Series in MongoDB in Ubuntu 20.04?
A Time Series database is a customized database that is built for storing data created from a constant stream of values coupled with a timestamp efficiently. The most common application is storing data from sensorial equipment that delivers data points at regular intervals, but they are now employed to serve a far broader range of applications.
The following are some examples of possible applications:
- Data from the internet of things
- Web services, apps, and infrastructure are all under constant surveillance.
- Estimating sales
- Financial Trends Understanding
- Data from self-driving cars or other physical objects are being processed.
A Time-Series specialized database uses compression technologies to reduce the amount of space needed while simultaneously providing access channels to dig deeper into the data. This enhances data retrieval and aggregation performance when using time range filters. They are more cost-effective than utilizing a traditional relational database.
The values in a Time Series should usually not change once they’ve been recorded; hence they’re designated as INSERT only or immutable data points. The update action is extremely rare once the data has been saved.
Guidelines for MongoDB Time Series Data Storage in Ubuntu 20.04
We have some guidelines for time-series data in MongoDB, which are outlined below.
- Consider the data features and query patterns while tuning your data for appropriate metaField and timeField.
- When possible, combine time series data and time-series collections.
- Individual measurements or sets of measurements should be saved as one document and added in batches when utilizing a time series collection.
- Customize our data granularity about the attribute values of our metaField, or the distinct pairings of our unique metaField, based on our data intake pace.
How to Use Time-Series MongoDB in Ubuntu 20.04
When working with time-series data, you typically need more than just storage; you also need fast read and write functionality as well as advanced query capabilities. MongoDB now handles time-series data natively, as of MongoDB 5.0. The following options should be specified when giving a time-series collection in MongoDB:
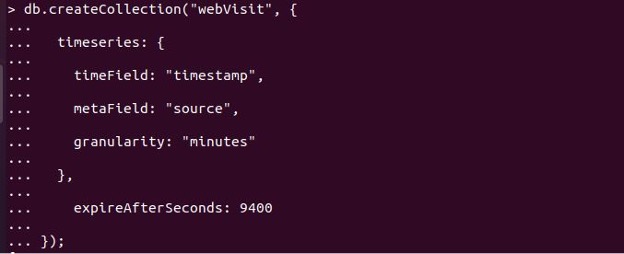
The createCollection() command can be used to start a new time series collection.
timeField: The timeField option must be used when creating a time series collection. The timeField denotes the description of the property in each document that contains the date. We should also consider the following alternatives:
metaField: The metaField specifies the name of the column in each document that contains metadata. The metaField acts as a label or tag that allows time-series collections to identify a time series’ source. This field should not, and should only, change over time.
Granularity: If a matching metaField is supplied, the granularity attribute specifies the temporal gap between documents. The standard granularity is “seconds,” indicating a high-frequency intake rate for each time series defined by the metaField. Granularity could be adjusted to “seconds,” “minutes,” or “hours,” and it can be changed at any moment to make it worse. However, because you can’t change the granularity from “minutes” to “seconds,” it’s best to start with finer granularity and work your way up to a harsher granularity.
expireAfterSeconds: Finally, if you intend to delete data after a specified period, we can include the expireAfterSeconds field specifies how many seconds should pass before documents expire and are automatically destroyed.
Insert Documents With Time Series in MongoDB
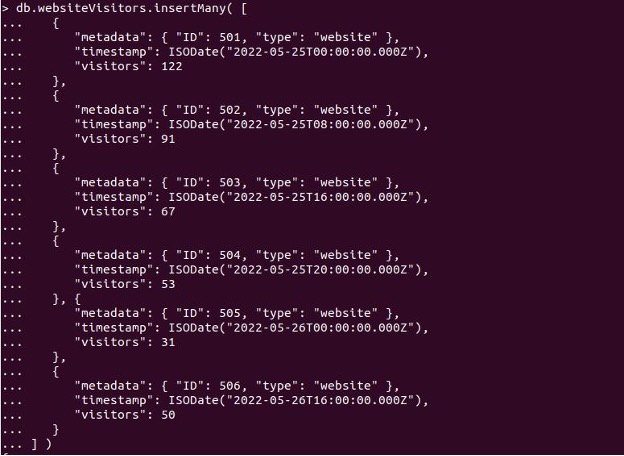
At the very least, each document added to the time series collection must define the timeField. The date is the timeField in the illustration document below. It’s worth noting that timeField can be termed whatever you want as long as it’s of the BSON type or a Date. Any of the techniques for inserting documents into other MongoDB collections can be used to add documents to a time series collection. For this, we have created a collection of “webVisitors” as follows:

A single measurement should be included in each document we insert. Use the following command to insert many documents at once:
Retrieving Time-Series Data in MongoDB in Ubuntu 20.04
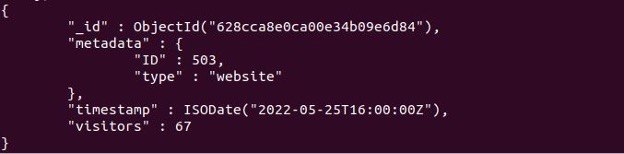
Time series documents can be queried like the documents from other collections of MongoDB. For example, with the MongoDB Shell, we have used a findOne to look for a document in the webVisitors collection() as follows.

The preceding query shows the following results, as you can see:
Aggregation on Time-Series Data in MongoDB in Ubuntu 20.04
Here, we have used an aggregate pipeline such as to add more query functionality. The following example aggregation pipeline combines all documents by measurement data and then delivers the average of all the visitor’s measurements taken on that day of a website:
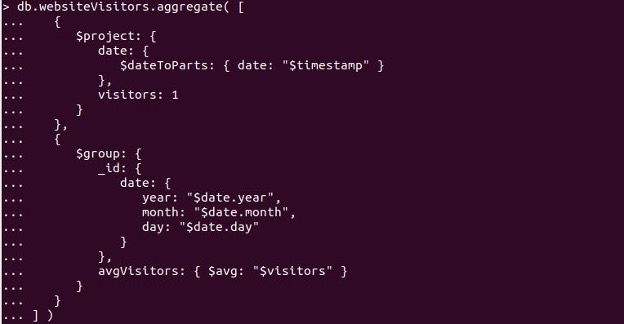
When we execute the aggregation pipeline on the collection websiteVisitors, the output generated the average of the visitor’s document from the collection “websiteVisitors” as follows:

Conclusion
There is a lot of time-series data, but maintaining and accessing it can be difficult. MongoDB gained native support for time-series, making working with time-series data considerably easier, faster, and less expensive. We have given a brief introduction with some guidelines for using time-series in MongoDB. We have some illustrations of time series which demonstrate how we can use time series in the MongoDB collection in some possible ways.
Source: linuxhint.com