How to Process a Large-Scale Data with MongoDB MapReduce
Create a Collection to Perform the MapReduce Operation
Let’s get started in performing the MapReduce() function on the specific collection. Here, we switch our default collection to the “student” collection where we can insert some documents to perform the MapReduce() function.

Insert the Documents into the Collection to Perform the MapReduce Operation
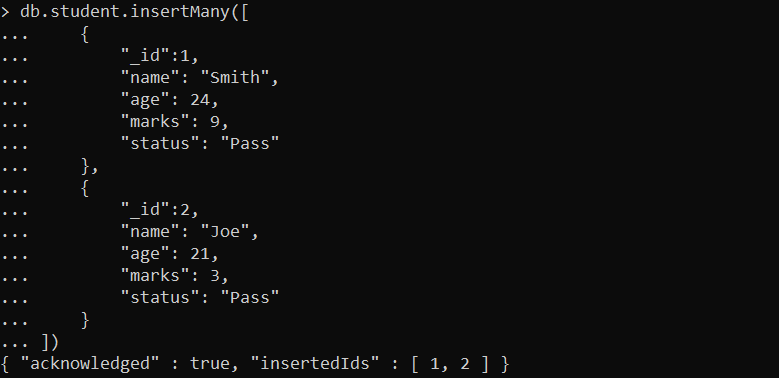
Now that our “student” collection is created, we can insert the documents at the same time using the insertMany() function. The query is mentioned in the following where we insert two documents that contain the same fields but with different values:
{
"_id":1,
"name": "Smith",
"age": 24,
"marks": 9,
"status": "Pass"
},
{
"_id":2,
"name": "Joe",
"age": 21,
"marks": 3,
"status": "Pass"
}
])
The output here shows that the documents are inserted with their IDs accordingly into the “student” collection:
Apply the MapReduce Operation to Get the Sum of the Specified Field
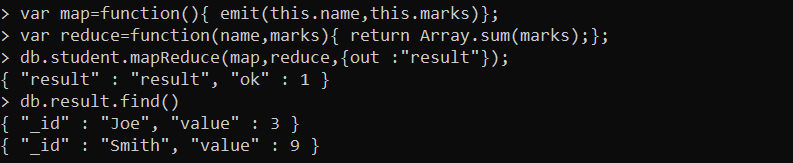
Now, let’s use the MapReduce() function to have the sum of the marks fields and store a result in a collection that we set in the query. Here’s the MapReduce() function query that is applied to the “student” collection:
var reduce=function(name,marks){ return Array.sum(marks);};
db.student.mapReduce(map,reduce,{out :"result"});
db.result.find()
We define the “map” variable using the var modifier and pass the map function() to it. This function here is anonymous as no name is assigned to it. After that, we call the emit() function inside the body of the anonymous function, a built-in function provided by MongoDB for map-reduce operations. We use it to generate the key-value pairs for the reduce phase.
Here, we output the key and value of each student’s field as their name and their mark. Next, we create the “reduce” variable where the function() is set to receive the key which is the student name, and an array of values of marks as input and return the total marks for each student using the Array.sum() function.
Lastly, we call the mapReduce() operation on the “student” collection and store the output into the “result” collection, and then call out that collection with the find() method.
The output is displayed where the “name” field and the marks of the student appear as a key-value pair by the mapReduce() function:
Apply the MapReduce Operation to Get the Average of the Specified Field
Now is the example of performing the mapReduce() function to get the average of the marks that are grouped by the “age” field. The code is the same as the previous example, but we use the Arrayhere.avg() function.
var reduce=function(age,marks){ return Array.avg(marks);};
db.student.mapReduce(map,reduce,{out :"output"});
db.output.find()
There, we define the variable map for the mapping of the “age” field and the “marks” field. For this, we employ the anonymous function() where no parameter is passed but, inside the body, the emit function is deployed to emit the “age” and the “marks” fields as the key-value pair for the reduce function. Then, we create the reduce function where the function() is passed with the argument as “age” and “marks” fields. These parameters are passed by MongoDB during the reduce phase when it groups the key-value pairs that are generated by the map phase based on their keys.
Then, we have the function() body where the return statement is defined to call out the function upon execution. Here, we use the Array.avg() function which calculates the average of the values in the “marks” array, which is an array of all the values that are associated with a particular key. Finally, the result is stored in the values in the “output” collection for each age group.
The following output is retrieved as the key-value pair of the age and the average of the marks after the execution of the mapReduce operation:

Apply the MapReduce Operation to Get the Even_Id Field
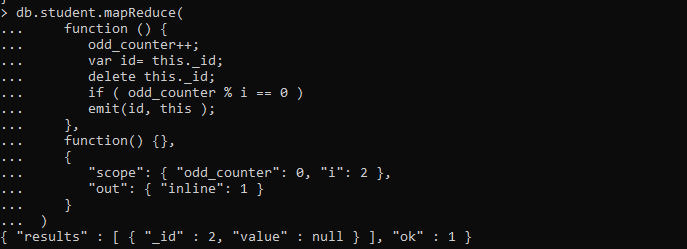
Moreover, we have a query that uses the mapReduce() function to display the alternate documents and generate the even field values.
function () {
odd_counter++;
var id= this._id;
delete this._id;
if ( odd_counter % i == 0 )
emit(id, this );
},
function() {},
{
"scope": { "odd_counter": 0, "i": 2 },
"out": { "inline": 1 }
}
)
As seen in the query, we initiate the mapReduce operation here on the “student” collection. After that, we define the function with the empty parameters and increment the value of the odd_counter variable inside it which is used within the scope of the map function.
Then, we store the existing IDs of the document in a “field_id” variable. Every record in the collection has a specific identification number or “_id” in the “_id” field. Next, we employ the delete operation on the “_id” field from the current document to exclude the original “_id” field from being included in the emitted documents. The “if” method is defined after that where we check if the counter is an odd multiple of “i”. If the condition becomes true, the emit() function emits a new key-value pair.
Here, the key is the original “id” of the document and the value is the current document, excluding the “_id” field. This means that only the documents whose _id is an odd multiple of “i” should be emitted. Next, we call the empty function() since no argument is passed.
After that, we set the scope for the map function which defines the variables that are accessible within the map function. In this case, we initialize two variables: the odd_counter with an initial value of 0 and “i” with an initial value of 2.
After the mapReduce() operation, the results are shown in the output where the even _id is achieved according to the specified condition:
Conclusion
The mapReduce() function is covered with the example illustration in this article. The examples include the sum and average of the values to get the grouped output by the mapReduce() function. Then, we performed the mapReduce() function to display the even values from the documents. Now, we can use the mapReduce() function to handle the large-scale data in MongoDB. Note that it may not always be the most efficient option for a large-scale data processing in MongoDB.
Source: linuxhint.com