How to Create a Round Robin Load Balancer in Kubernetes
What Is a Load Balancer?
Kubernetes container management is vital for the smooth running of an application. A load balancer is a prime requirement to achieve a good container management and high scalability in Kubernetes. As discussed earlier, a load balancer sits between the client-server and the source service. The sole purpose of a load balancer is to ensure that the network flow is regulated between different servers. In Kubernetes, the network traffic is directed from the resource server to multiple Kubernetes services. Thus, a regulatory body is needed to manage this flow of data among different servers and Kubernetes services. A load balancer prevents the overloading of a server and improves the server response time in Kubernetes. This lets the users use the containers more efficiently.
Until its capacity is achieved, the Kubernetes load balancer sends connections to the pool’s first server. The following server up receives the new connections after that. This strategy is useful in situations where virtual machines are expensive, such as hosted settings.
In Kubernetes, the service configuration file looks something like the following:

You can see that the type is loadBalancer in the screenshot that is previously provided. By entering the LoadBalancer in the type area of the service configuration file, the load balancer is turned on. Additional details like the apiversion, kind, name, and spec information are also displayed. The load balancer in this instance, which routes the traffic to the back-end PODs, is managed and directed by the cloud service provider.
Working Principle of Load Balancer
First, let us clear up a common misconception. When you hear the word load balancer in Kubernetes, it might confuse you as the term load balancer in Kubernetes is used interchangeably for many purposes. However, in this article, we will focus on two things – relating the services of Kubernetes with external environments and managing the network load with these services.
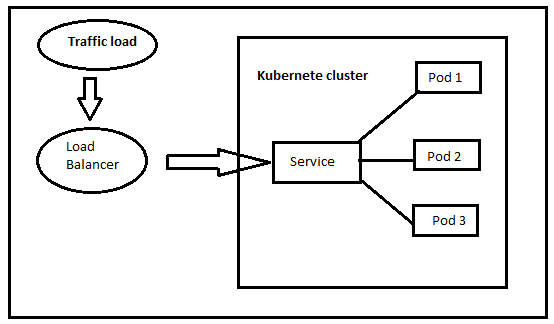
The pods in Kubernetes refer to the smallest deployable units that contain the scheduled tasks. A group of pods makes a container. The components of Kubernetes are structured based on the function. All containers that are to perform a similar function are organized into pods. Similarly, all related pods are then combined to create a service. Let us keep in mind that the pods in Kubernetes are not permanent. They keep getting destroyed and created every time the pod is restarted.
Consequently, the IP addresses of the pods also keep getting changed time and time again. When the pod is restarted, Kubernetes automatically assigns new IP addresses to the newly created pods. On the other hand, when we talk about a group of pods which are collectively known as services, they possess a persistent IP address. Unlike an individual, it doesn’t get changed after restarting. This is called cluster IP. The containers in that specific cluster can only access cluster IP. However, you cannot access the cluster IP from an external environment. That’s where the load balancer is important. Since you cannot directly access the cluster IP from outside the cluster, you need an intervention. This intervention deals with all requests from outside the cluster and manage the network traffic.
Creation of Round Robin Load Balancer
There are many kinds of load balancers. In this article, we are particularly targeting one kind. We will talk about the type of load balancer which is dedicated to network flow balancing. In Kubernetes, this load balancer deals with the appropriate distribution of network traffic to the Kubernetes services. This distribution is done according to a set of preprogrammed instructions or algorithms.
The round robin load balancer is one of the simplest ways to manage the input requests among server pools. It is one of the strategies to use the features of Kubernetes, such as management and scalability, to the fullest. The key behind the better and more efficient use of Kubernetes services is balancing the traffic to the pods.
The round robin algorithm is designed to direct the traffic to a set of pods in a specific order. Here, it’s the planned order that needs to be noted. That means the configuration lies in your hands.
Step 1: Let us suppose you configured five pods in a round-robin algorithm. The load balancer will send the requests to each pod in a specific sequence. The initial pod receives the first request. The second pod receives the second request.
Step 2: Similarly, a third request is sent to the third pod, and so on. But the sequence does not change. One important thing is that a round-robin algorithm never deals with the variables such as the current load in a server. That means it is static. This is why it is not preferred in production traffic.
The main reason that you should be leaning towards the round-robin algorithm is that its implementation is a piece of cake. However, this might compromise the accuracy of traffic. This is because the round robin load balancers cannot identify the different servers. Different variants of load balancers exist to improve accuracy, such as weighted round robin, dynamic round robin, etc.
Conclusion
This article provides the readers with foundation information about load balancers and how they work. One of the most important tasks of Kubernetes administrators is load balancing. Additionally, we talked about the structure of Kubernetes and how important a load balancer is to improve the running of Kubernetes clusters. In this article, we learned about a type of load balancer which is the round robin load balancer.
Source: linuxhint.com