How to Apply Pipelines on a Dataset in Transformers?
The pipeline() function is an integral part of the Transformer library. It takes several inputs in which we can define an inference task, models, tokenization mechanism, etc. A pipeline() function is majorly used to perform NLP tasks on one or several texts. It performs pre-processing on the input and post-processing based on the model to generate human-readable output and accurate prediction with maximum accuracy.
This article covers the following aspects:
What is the Hugging Face Dataset Library?
A Hugging Face dataset library is an API that contains several public datasets and provides an easy way to download them. This library can be imported and installed into the application by using the “pip” command. For a practical demonstration to download and install datasets of the Hugging Face library, visit this Google Colab link. You can download multiple datasets from the Hugging Face Dataset Hub.
Learn more about the functioning of the pipeline() function by referring to this article “How to Utilize the Pipeline() Function in Transformers?”.
How to Apply Pipelines on a Dataset in Hugging Face?
Hugging Face provides several different public datasets that can easily be installed by using one-line code. In this article, we will see a practical demonstration of applying pipelines to these datasets. There are two ways in which pipelines can be implemented on the dataset.
Method 1: Using Iteration Method
The pipeline() function can be iterated over a dataset and model too. For this purpose, follow the below-mentioned steps:
Step 1: Install Transformer Library
To install the Transformer library, provide the following command:
Step 2: Import Pipelines
We can import the pipeline from the Transformer library. For this purpose, provide the following command:

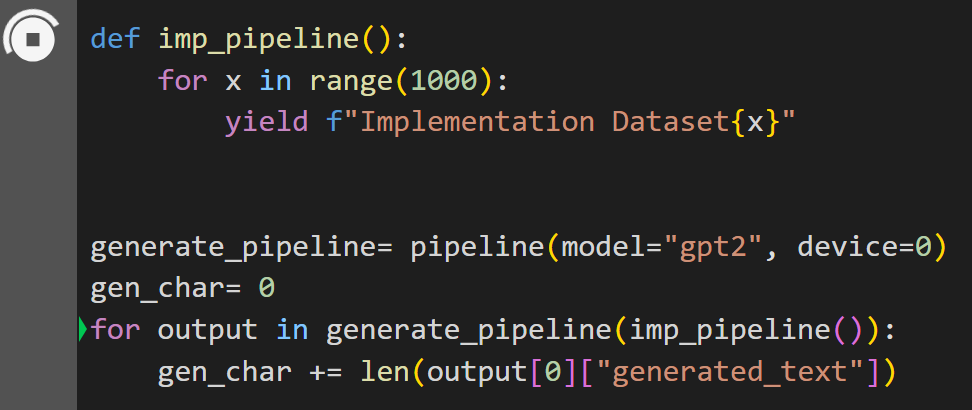
Step 3: Implement Pipeline
Here, the pipeline() function is implemented on the model “gpt2”. You can download models from the Hugging Face Model Hub:
for x in range(1000):
yield f"Implementation Dataset{x}"
generate_pipeline= pipeline(model="gpt2", device=0)
gen_char= 0
for output in generate_pipeline(imp_pipeline()):
gen_char += len(output[0]["generated_text"])
In this code, the “generate_pipeline” is a variable that contains the pipeline() function with model “gpt2”. When it is called with the “imp_pipeline()” function, it automatically recognizes the data that is increased with the range specified to 1000:
This will take some time to train. The link to the Google Colab is also given.
Method 2: Using Datasets Library
In this method, we will demonstrate implementing the pipeline using the “datasets” library:
Step 1: Install Transformer
To install the Transformer library, provide the following command:
Step 2: Install Dataset Library
As the “datasets” library contains all the public datasets, we can install it by using the following command. By installing the “datasets” library, we can directly import any dataset by providing its name:

Step 3: Dataset Pipeline
To build a pipeline on the dataset, use the following code. KeyDataset is a feature that outputs only those values that interest the user:
from transformers import pipeline
from datasets import load_dataset
gen_pipeline = pipeline(model="hf-internal-testing/tiny-random-wav2vec2", device=0)
loaddataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation[:10]")for output in gen_pipeline(KeyDataset(loaddataset, "audio")):
print("Printing output now")
print ("—————-")
print(output)
The output of the above code is given below:
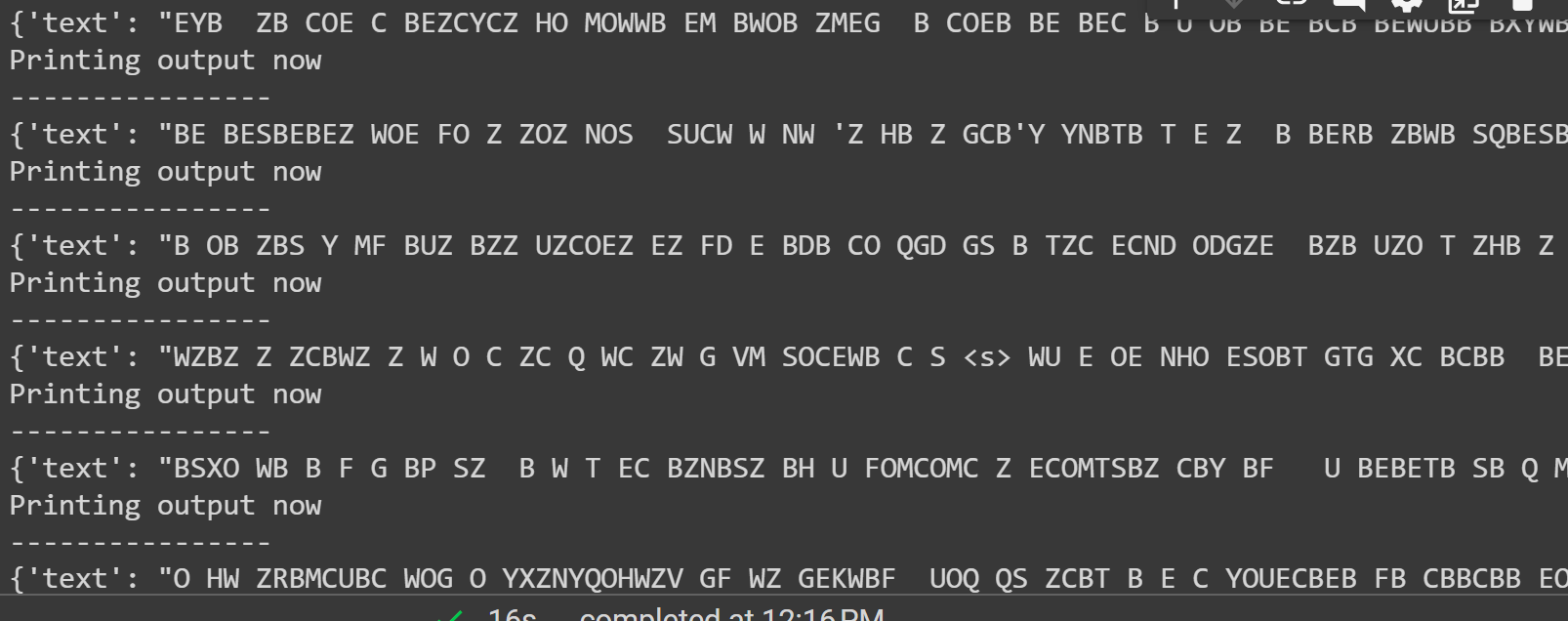
That is all from this guide. The link to the Google Colab is also mentioned in this article
Conclusion
To apply pipelines on the dataset, we can either iterate over a dataset by using a pipeline() function or use the “datasets” library. Hugging Face provides the GitHub repository link to its users for both datasets and models which can be used based on the requirements. This article has provided a comprehensive guide to applying pipelines on a dataset in Transformers.
Source: linuxhint.com