Hash Table in C++
Hash Function
In this section, we will discuss about the hash function that helps to execute the hash code of the related key of the data item in the data structure as mentioned in the following:
{
return key % tablesize;
}
The process of executing the index of an array is called hashing. Sometimes, the same type of code is executed to generate the same index using the same keys called collisions which is handled through different chaining (linked list creation) and open addressing strategies implementation.
Working of Hash Table in C++
The pointers to the real values are kept in the hash table. It uses a key to search out the index of an array at which the values against the keys need to be stored in the desired location in an array. We took the hash table having size 10 as mentioned in the following:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
Let us randomly take any data against different keys and store these keys in a hash table by just calculating the index. So, the data is stored against the keys in the calculated index with the help of a hash function. Suppose we take a data = {14,25,42,55,63,84} and keys =[ 15,9,5,25,66,75 ].
Calculate the index of these data using the hash function. The index value is mentioned in the following:
| Key | 15 | 9 | 29 | 43 | 66 | 71 |
|---|---|---|---|---|---|---|
| Calculate Index | 15%10 = 5 | 9%10=0 | 29%10=9 | 43%10=3 | 66%10=6 | 71%10=1 |
| Data | 14 | 25 | 42 | 55 | 63 | 84 |
After creating the index of an array, place the data against the key on the exact index of a given array as described previously.
| 25 | 84 | 55 | 14 | 63 | 42 | ||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
After that, we can see that a collision occurs if two or more keys have the same hash code which results in the same index of the elements in the array. We have one solution to avoid the chances of collision: selecting a good hash method and implementing the accurate strategies.
Now, let’s discuss the different implementation techniques with the help of proper examples.
Example: Add a Data in a Hash Table Using an Open Hashing Technique
In this example, we take an implementation technique like Open Hashing to avoid collision in the hash table. In open hashing or chaining, we create a linked list to chain the values of the hash table. The code snippet of this example is attached in the following that describes the open hashing technique:
#include <list>
class HashTable {
private:
static const int tableSize = 10;
std::list<int> tableHas[tableSize];
int hashFunc(int key) {
return key % tableSize;
}
public:
void insert(int key) {
int index = hashFunc(key);
tableHas[index].push_back(key);
}
void viewTable() {
for (int i = 0; i < tableSize; ++i) {
std::cout << "[" << i << "]";
for (auto it = tableHas[i].begin(); it != tableHas[i].end(); ++it) {
std::cout << " -> " << *it;
}
std::cout << std::endl;
}
}
};
int main() {
HashTable hasTable;
hasTable.insert(15);
hasTable.insert(33);
hasTable.insert(23);
hasTable.insert(65);
hasTable.insert(3);
hasTable.viewTable();
return 0;
}
This is a very interesting example: we build a linked list and insert the data in the hash table. First of all, we define the libraries at the start of the program. The <list> library is used for the linked list implementation. After that, we build a class named “HashTable” and create the attributes of the class that are private as table size and table array using the “private:” keyword. Remember that the private attributes are not usable outside the class. Here, we take the size of the table as “10”. We initialize the hash method using this and calculate the index of the hash table. In the hash function, we pass the key and size of the hash table.
We build a few required functions and make these functions public in the class. Remember that public functions are usable outside the class anywhere. We use the “public:” keyword to start the public portion of the class. Since we want to add new elements to the hash table, we create a function named “InsertHash” with a key as an argument of the function. In the “insert” function, we initialize the index variable. We pass the hash function to the index variable. After that, pass the index variable to the linked list tableHas[]using the “push” method to insert an element in the table.
After that, we build a “viewHashTab” function to display the hash table to see the newly inserted data. In this function, we take a “for” loop that searches the values until the end of the hash table. Ensure that the values are stored at the same index that are developed using a hash function. In the loop, we pass the values at their respective index and end the class here. In the “main” function, we take the object of a class named “hasTable”. With the help of this class object, we can access the method of insertion by passing the key in the method. The key that we passed in the “main” function is computed in the “insert” function that returns the index position in the hash table. We displayed the hash table by calling the “view” function with the help of a “Class” object.
The output of this code is attached in the following:
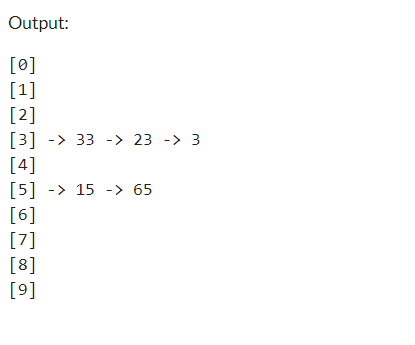
As we can see, the hash table is created successfully using the linked list in C++. Open chaining is used to avoid the collision of the same index.
Conclusion
Ultimately, we concluded that a hash table is the most emerging technique to store and get the keys with value pairs to handle huge amounts of data efficiently. The chances of collision are very high in the hash table, destroying the data and its storage. We can overcome this collision using different techniques of the hash table management. By developing the hash table in C++, the developers can increase the performance using the best suitable technique to store the data in the hash table. We hope that this article is helpful for your understanding of the hash table.
Source: linuxhint.com