Gawk Scripting Usage Examples
Getting Started with Gawk
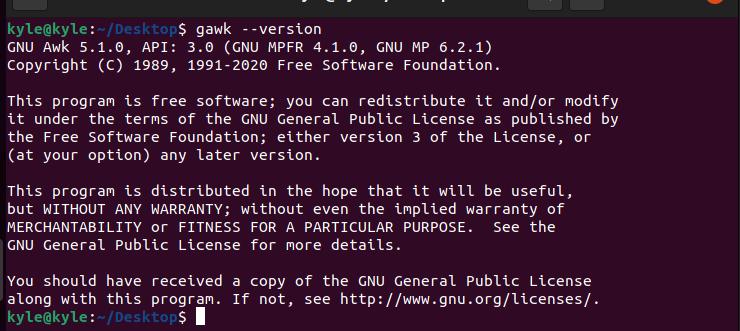
If you are using the latest Linux versions, gawk should be installed by default. You can verify by checking its version.
There are different ways to use gawk. The common functionalities are the following:
- Format output lines
- Transforming data files
- Scanning files per line
- Splitting input line into fields
- Producing formatted reports
- Sorting data
The basic syntax for gawk is:
$ gawk [POSIX / GNU style options] [ — ] ‘program’ file …
To use gawk, you either use the -f option to specify a script file or specify the script on the command line directly.
There are three important options to note when using gawk:
1. -f file, –file=file: Used when you want to use gawk and read commands from a file. The file is the script.
2. -v var=val, –assign=var=val: Used when you need to assign a value to a variable before executing a script.
3. -F fs, –field-separator=fs: The value of the predefined variable FS gets used as the separator for the input field.
Built-In Variables
Gawk offers built-in variables such as:
FS: Used when dividing files and contains the field separator character.
RS: Contains the current character separator.
OFS: Contains the output field separator that separates the fields that AWK prints.
NF: The number of fields for the input record gets stored in the NF.
ORS: Contains the output field separator that separates the output lines printed by AWK.
NR: Contains the total number of input lines.
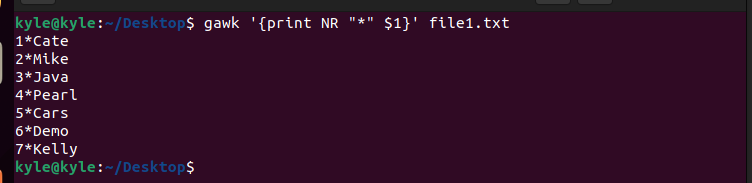
In the previous example, we use * as the separator for the input lines in the file.
Example Usage of Gawk
1. -F
For sorting a text file and printing the first three colon-separated fields, use the following command. Note that we use the passwd as our file here:
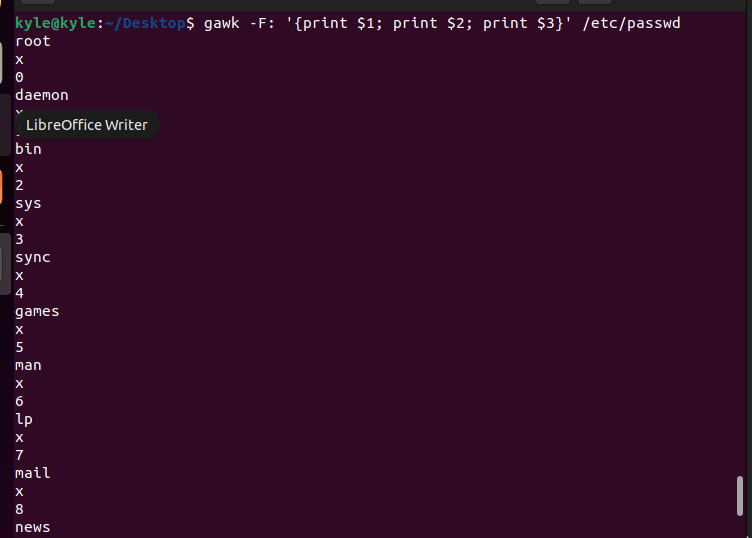
Here, our separator is a full colon. Since we want the first three fields, you specify them as shown in the previous example. You can tweak it around and use a different separator and a different number of fields.
2. -f
To specify the awk program source from a file, use the -f flag followed by the file:
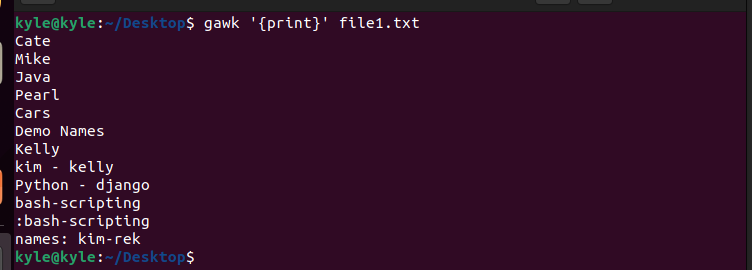
3. Printing Contents of a File
Using gawk on a file prints all the data lines in the file.
4. Working with Patterns
You can also use gawk and print only the lines matching a given pattern. For instance, to print a line containing a particular word, in our case the word is kim, the command would be:

Here, the pattern can also be a character. For instance, to print all the lines that contain a colon, the command would be as in the following image:

You can also specify the specific lines to print. For instance, to print the lines containing specific characters such as greater than 6, the syntax is:
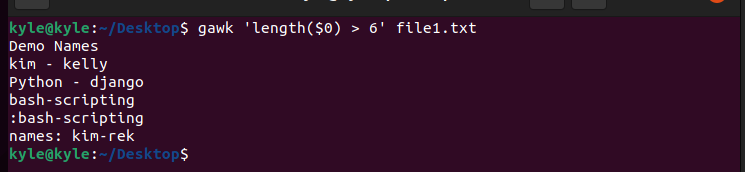
5. Splitting Lines Into Fields
Gawk, by default, prints every field when printing lines in a file. However, you can specify which field to print. The first field gets stored in the $1 and the whole line is represented as $0. By default, the entire line gets printed unless you specify to separate the fields based on the whitespace.
For instance, to separate the lines and print only the second field of each line, the command would be:
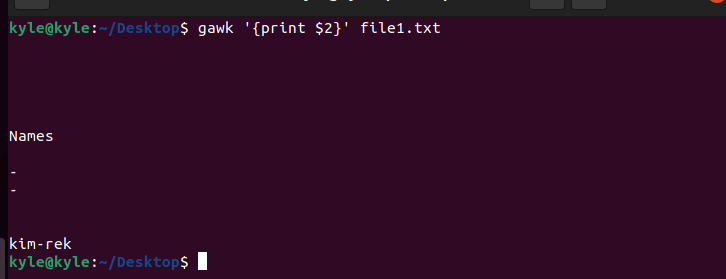
To add the line numbers, add the NR variable.
The new command would be:
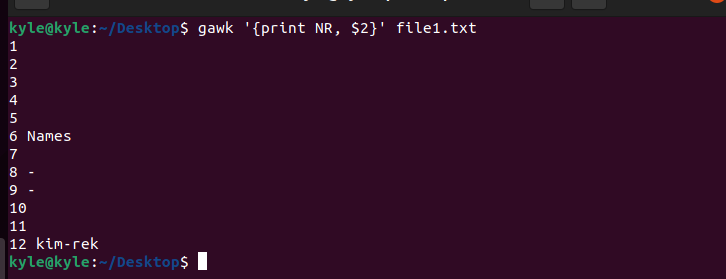
6. Get the Number of Lines
You may need to get the total number of lines for large files, and you can achieve that using the following syntax:

Conclusion
Knowing how to use gawk in Linux is fun and helpful, especially when dealing with text data. You can use the different patterns to extract and manipulate the lines of data. Hopefully, the examples covered in this article give you a head start and open your eyes in using gawk for different activities.
Source: linuxhint.com