Elasticsearch Multi-Get
This article will discuss on how to use the Elasticsearch multi-get API to fetch multiple JSON documents based on their IDs. In addition, Elasticsearch allows you to use a single get query to retrieve the documents from indices using only the document IDs.
Let’s explore.
Request Syntax
The following is the syntax for the Elasticsearch multi-get API:
GET /<index>/_mget
The multi-get API supports multiple indices which allows you to fetch the documents even if they are not in the same index.
The request supports the following path parameters:
- <index> – The name of the index from which to retrieve the documents as specified by their IDs.
You can also specify the other query parameters as shown:
- Preference – Defines the preferred node or shard.
- Realtime – If set to true, the operation is performed in real-time.
- Refresh – Forces the operation to refresh the target shards before fetching the specified documents.
- Routing – A value that is used to route the operations to a specific shard.
- Store_fields – Retrieves the document fields stored in an index rather than the document.
- _source – A Boolean value that defines if the request should return the _source field or not.
The Query requires the body, which includes the following values:
- Docs – Specifies the documents that you wish to fetch. In addition, this section supports the following attributes:
- _id – Unique ID of the target document.
- _index – The index that contains the target document.
- Routing – The key for the primary shard of the document.
- _source – If true, it includes all source fields; otherwise, it excludes them.
- _stored_fields – The stored_fields that you wish to include.
- Ids – The ids of the documents that you wish to fetch.
Example 1: Fetch Multiple Documents from the Same Index
The following example shows how to use the Elasticsearch multi-get API to retrieve the documents with specific IDs from the Netflix index:
{
"docs": [
{
"_id": "T3wnVoMBck2AEzXPytlJ"
},
{
"_id": "W3wnVoMBck2AEzXPytlJ"
}
] }'
The given request should fetch the documents with the specified IDs from the Netflix index. The resulting output is as shown:
"docs": [
{
"_index": "netflix",
"_id": "T3wnVoMBck2AEzXPytlJ",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"duration": "90 min",
"listed_in": "Documentaries",
"country": "United States",
"date_added": "September 25, 2021",
"show_id": "s1",
"director": "Kirsten Johnson",
"release_year": 2020,
"rating": "PG-13",
"description": "As her father nears the end of his life, filmmaker Kirsten Johnson stages his death in inventive and comical ways to help them both face the inevitable.",
"type": "Movie",
"title": "Dick Johnson Is Dead"
}
},
{
"_index": "netflix",
"_id": "W3wnVoMBck2AEzXPytlJ",
"_version": 1,
"_seq_no": 12,
"_primary_term": 1,
"found": true,
"_source": {
"country": "Germany, Czech Republic",
"show_id": "s13",
"director": "Christian Schwochow",
"release_year": 2021,
"rating": "TV-MA",
"description": "After most of her family is murdered in a terrorist bombing, a young woman is unknowingly lured into joining the very group that killed them.",
"type": "Movie",
"title": "Je Suis Karl",
"duration": "127 min",
"listed_in": "Dramas, International Movies",
"cast": "Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová",
"date_added": "September 23, 2021"
}
}
]
}
We can also simplify the request by putting the document IDs in a simple array as shown in the following:
{
"ids": ["T3wnVoMBck2AEzXPytlJ", "W3wnVoMBck2AEzXPytlJ"] }'
The previous request should perform a similar action.
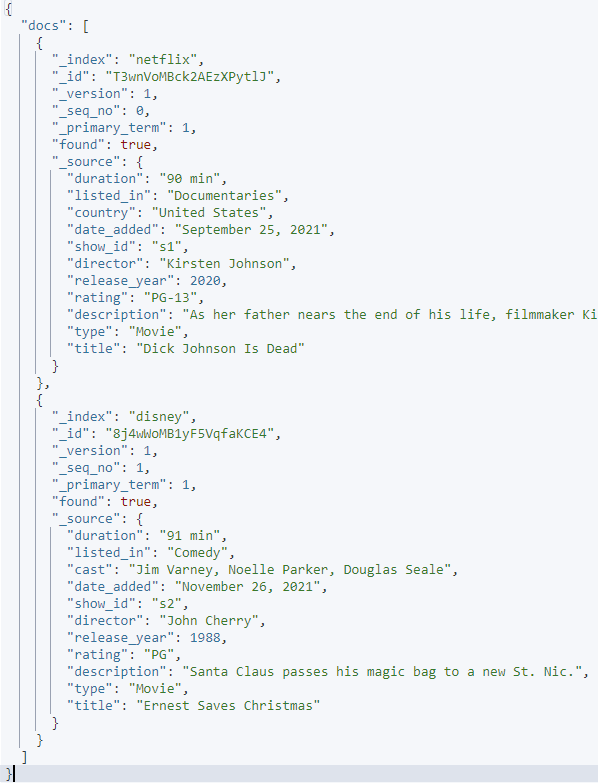
Example 2: Fetch the Documents from Multiple Indicies
In the following example, the request fetches multiple documents from different indices as shown:
{
"docs": [
{
"_index": "netflix",
"_id": "T3wnVoMBck2AEzXPytlJ"
},
{
"_index": "disney",
"_id": "8j4wWoMB1yF5VqfaKCE4"
}
] }'
The resulting output is as shown:
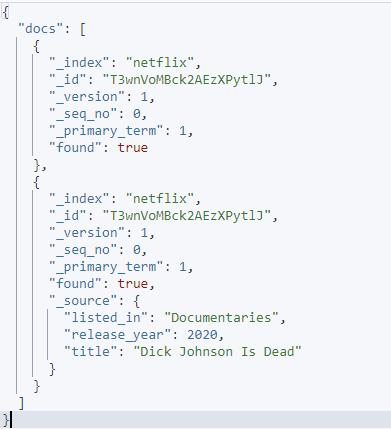
Example 3: Exclude Specific Fields
We can exclude specific fields from a given request using the source_include and source_exclude parameters.
An example is as shown:
{
"docs": [
{
"_index": "netflix",
"_id": "T3wnVoMBck2AEzXPytlJ",
"_source": false
},
{
"_index": "netflix",
"_id": "T3wnVoMBck2AEzXPytlJ",
"_source": {
"include": [ "listed_in", "release_year", "title" ],
"exclude": [ "description", "type", "date_added" ] }
}
]
}'
The given request uses the source include and exclude to specify which fields you wish to retrieve in a given document.
The resulting output is as shown:
Conclusion
In this post, we discussed the fundamentals of working with Elasticsearch multi-get API which allows you to fetch multiple documents from various sources based on their IDs. Feel free to explore the other documents for more information.
Happy coding!
Source: linuxhint.com