Check the Given Data is PySpark RDD or DataFrame
In Python, PySpark is a Spark module used to provide a similar kind of processing like spark.
RDD stands for Resilient Distributed Datasets. We can call RDD a fundamental data structure in Apache Spark.
Syntax:
|
1
|
spark_app.sparkContext.parallelize(data)
|
We can display the data in a tabular format. The data structure used is DataFrame.Tabular format means it stores data in rows and columns.
Syntax:
In PySpark, we can create a DataFrame from spark app with the createDataFrame() method.
Syntax:
|
1
|
Spark_app.createDataFrame(input_data,columns)
|
Where input_data may be a dictionary or a list to create a dataframe from this data, and if the input_data is a list of dictionaries, then the columns are not needed. If it is a nested list, we have to provide the column names.
Now, let’s discuss how to check the given data in PySpark RDD or DataFrame.
Creation of PySpark RDD:
In this example, we will create an RDD named students and display using collect() action.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
# import RDD from pyspark.rdd
from pyspark.rdd import RDD
#create an app named linuxhint
spark_app = SparkSession.builder.appName(‘linuxhint’).getOrCreate()
# create student data with 5 rows and 6 attributes
students =spark_app.sparkContext.parallelize([
{‘rollno’:‘001’,‘name’:‘sravan’,‘age’:23,‘height’:5.79,‘weight’:67,‘address’:‘guntur’},
{‘rollno’:‘002’,‘name’:‘ojaswi’,‘age’:16,‘height’:3.79,‘weight’:34,‘address’:‘hyd’},
{‘rollno’:‘003’,‘name’:‘gnanesh chowdary’,‘age’:7,‘height’:2.79,‘weight’:17,‘address’:‘patna’},
{‘rollno’:‘004’,‘name’:‘rohith’,‘age’:9,‘height’:3.69,‘weight’:28,‘address’:‘hyd’},
{‘rollno’:‘005’,‘name’:‘sridevi’,‘age’:37,‘height’:5.59,‘weight’:54,‘address’:‘hyd’}])
#display the RDD using collect()
print(students.collect())
Output:
{‘rollno’: ‘002’, ‘name’: ‘ojaswi’, ‘age’: 16, ‘height’: 3.79, ‘weight’: 34, ‘address’: ‘hyd’},
{‘rollno’: ‘003’, ‘name’: ‘gnanesh chowdary’, ‘age’: 7, ‘height’: 2.79, ‘weight’: 17, ‘address’: ‘patna’},
{‘rollno’: ‘004’, ‘name’: ‘rohith’, ‘age’: 9, ‘height’: 3.69, ‘weight’: 28, ‘address’: ‘hyd’},
{‘rollno’: ‘005’, ‘name’: ‘sridevi’, ‘age’: 37, ‘height’: 5.59, ‘weight’: 54, ‘address’: ‘hyd’}]
Creation of PySpark DataFrame:
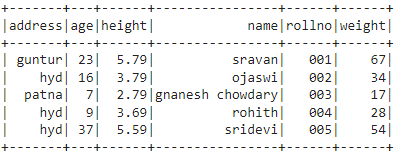
In this example, we will create a DataFrame named df from the students’ data and display it using the show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName(‘linuxhint’).getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{‘rollno’:‘001’,‘name’:‘sravan’,‘age’:23,‘height’:5.79,‘weight’:67,‘address’:‘guntur’},
{‘rollno’:‘002’,‘name’:‘ojaswi’,‘age’:16,‘height’:3.79,‘weight’:34,‘address’:‘hyd’},
{‘rollno’:‘003’,‘name’:‘gnanesh chowdary’,‘age’:7,‘height’:2.79,‘weight’:17,‘address’:‘patna’},
{‘rollno’:‘004’,‘name’:‘rohith’,‘age’:9,‘height’:3.69,‘weight’:28,‘address’:‘hyd’},
{‘rollno’:‘005’,‘name’:‘sridevi’,‘age’:37,‘height’:5.59,‘weight’:54,‘address’:‘hyd’}]
# create the dataframe
df = spark_app.createDataFrame( students)
#display the dataframe
df.show()
Output:
Method 1 : isinstance()
In Python, isinstance() method is used to compare the given object(data) with the type(RDD/DataFrame)
Syntax:
|
1
|
isinstance(object,RDD/DataFrame)
|
It takes two parameters:
Parameters:
- object refers to the data
- RDD is the type available in pyspark.rdd module and DataFrame is the type available in pyspark.sql module
It will return Boolean values (True/False).
Suppose the data is RDD and the type is also RDD, then it will return True, otherwise it will return False.
Similarly, if the data is DataFrame and type is also DataFrame, then it will return True, otherwise it will return False.
Example 1:
Check for RDD object
In this example, we will apply isinstance() for RDD object.
import pyspark
#import SparkSession and DataFrame for creating a session
from pyspark.sql import SparkSession,DataFrame
# import RDD from pyspark.rdd
from pyspark.rdd import RDD
#create an app named linuxhint
spark_app = SparkSession.builder.appName(‘linuxhint’).getOrCreate()
# create student data with 5 rows and 6 attributes
students =spark_app.sparkContext.parallelize([
{‘rollno’:‘001’,‘name’:‘sravan’,‘age’:23,‘height’:5.79,‘weight’:67,‘address’:‘guntur’},
{‘rollno’:‘002’,‘name’:‘ojaswi’,‘age’:16,‘height’:3.79,‘weight’:34,‘address’:‘hyd’},
{‘rollno’:‘003’,‘name’:‘gnanesh chowdary’,‘age’:7,‘height’:2.79,‘weight’:17,‘address’:‘patna’},
{‘rollno’:‘004’,‘name’:‘rohith’,‘age’:9,‘height’:3.69,‘weight’:28,‘address’:‘hyd’},
{‘rollno’:‘005’,‘name’:‘sridevi’,‘age’:37,‘height’:5.59,‘weight’:54,‘address’:‘hyd’}])
#check if the students object is RDD
print(isinstance(students,RDD))
#check if the students object is DataFrame
print(isinstance(students,DataFrame))
Output:
|
1
2 3 |
True
False |
First, we compared students with RDD; it returned True because it is an RDD; and then we compared students with DataFrame, it returned False because it is an RDD (not a DataFrame).
Example 2:
Check for DataFrame object
In this example, we will apply isinstance() for the DataFrame object.
import pyspark
#import SparkSession,DataFrame for creating a session
from pyspark.sql import SparkSession,DataFrame
#import the col function
from pyspark.sql.functions import col
# import RDD from pyspark.rdd
from pyspark.rdd import RDD
#create an app named linuxhint
spark_app = SparkSession.builder.appName(‘linuxhint’).getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{‘rollno’:‘001’,‘name’:‘sravan’,‘age’:23,‘height’:5.79,‘weight’:67,‘address’:‘guntur’},
{‘rollno’:‘002’,‘name’:‘ojaswi’,‘age’:16,‘height’:3.79,‘weight’:34,‘address’:‘hyd’},
{‘rollno’:‘003’,‘name’:‘gnanesh chowdary’,‘age’:7,‘height’:2.79,‘weight’:17,‘address’:‘patna’},
{‘rollno’:‘004’,‘name’:‘rohith’,‘age’:9,‘height’:3.69,‘weight’:28,‘address’:‘hyd’},
{‘rollno’:‘005’,‘name’:‘sridevi’,‘age’:37,‘height’:5.59,‘weight’:54,‘address’:‘hyd’}]
# create the dataframe
df = spark_app.createDataFrame( students)
#check if the df is RDD
print(isinstance(df,RDD))
#check if the df is DataFrame
print(isinstance(df,DataFrame))
Output:
|
1
2 3 |
False
True |
First, we compared df with RDD; it returned False because it is a DataFrame and then we compared df with DataFrame; it returned True because it is a DataFrame (not an RDD).
Method 2 : type()
In Python, the type() method returns the class of the specified object. It takes object as a parameter.
Syntax:
|
1
|
type(object)
|
Example 1:
Check for an RDD object.
We will apply type() to the RDD object.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
# import RDD from pyspark.rdd
from pyspark.rdd import RDD
#create an app named linuxhint
spark_app = SparkSession.builder.appName(‘linuxhint’).getOrCreate()
# create student data with 5 rows and 6 attributes
students =spark_app.sparkContext.parallelize([
{‘rollno’:‘001’,‘name’:‘sravan’,‘age’:23,‘height’:5.79,‘weight’:67,‘address’:‘guntur’},
{‘rollno’:‘002’,‘name’:‘ojaswi’,‘age’:16,‘height’:3.79,‘weight’:34,‘address’:‘hyd’},
{‘rollno’:‘003’,‘name’:‘gnanesh chowdary’,‘age’:7,‘height’:2.79,‘weight’:17,‘address’:‘patna’},
{‘rollno’:‘004’,‘name’:‘rohith’,‘age’:9,‘height’:3.69,‘weight’:28,‘address’:‘hyd’},
{‘rollno’:‘005’,‘name’:‘sridevi’,‘age’:37,‘height’:5.59,‘weight’:54,‘address’:‘hyd’}])
#check the type of students
print(type(students))
Output:
|
1
|
<class ‘pyspark.rdd.RDD’>
|
We can see that class RDD is returned.
Example 2:
Check for DataFrame object.
We will apply type() on the DataFrame object.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName(‘linuxhint’).getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{‘rollno’:‘001’,‘name’:‘sravan’,‘age’:23,‘height’:5.79,‘weight’:67,‘address’:‘guntur’},
{‘rollno’:‘002’,‘name’:‘ojaswi’,‘age’:16,‘height’:3.79,‘weight’:34,‘address’:‘hyd’},
{‘rollno’:‘003’,‘name’:‘gnanesh chowdary’,‘age’:7,‘height’:2.79,‘weight’:17,‘address’:‘patna’},
{‘rollno’:‘004’,‘name’:‘rohith’,‘age’:9,‘height’:3.69,‘weight’:28,‘address’:‘hyd’},
{‘rollno’:‘005’,‘name’:‘sridevi’,‘age’:37,‘height’:5.59,‘weight’:54,‘address’:‘hyd’}]
# create the dataframe
df = spark_app.createDataFrame( students)
#check the type of df
print(type(df))
Output:
|
1
|
<class ‘pyspark.sql.dataframe.DataFrame’>
|
We can see that class DataFrame is returned.
Conclusion
In the above article, we saw two ways to check if the given data or object is an RDD or DataFrame using isinstance() and type(). You must note that isinstance() results in boolean values based on the given object – if the object type is the same, then it will return True, otherwise False. And type() is used to return the class of the given data or object.
Source: linuxhint.com