C++ Std Atomic
We use the “std atomic” if we want to retain the atomicity of the operation in C++. Atomicity is the concept that we get to deal with when we are working in multithreading operations/applications where even the simple functions such as reading and writing in executing simultaneously can create issues or undefined behaviors in the code. To deal with such a situation, C++ has defined the “STD:: Atomic” library that guarantees a consistency that is sequential enough for the execution of reading and writing for various distinct objects which depicts the well-defined behavior. If one thread is writing at some time, the other thread is reading at that time.
Procedure:
This article will explore what Atomicity is and how we can use the concepts of std atomic to deal with the undefined behaviors in our codes. We will discuss the various functions of std atomic and implement the various examples for std atomic. The function under the std atomic that we will implement on the different examples are given as follows:
- Simplest reading and writing of values
- Release and acquire ordering with memory (model)
- Exchange model
- Fetch operation
Simplest Reading and Writing of Values
Let’s create a multithread application in this example where we create two threads: one thread for reading the values and the other thread for writing the values. With the help of this example, we will try to get the concept of std atomics, what is the undefined behaviors while running the multithread applications, and how the std atomic eliminates the undefined behaviors.
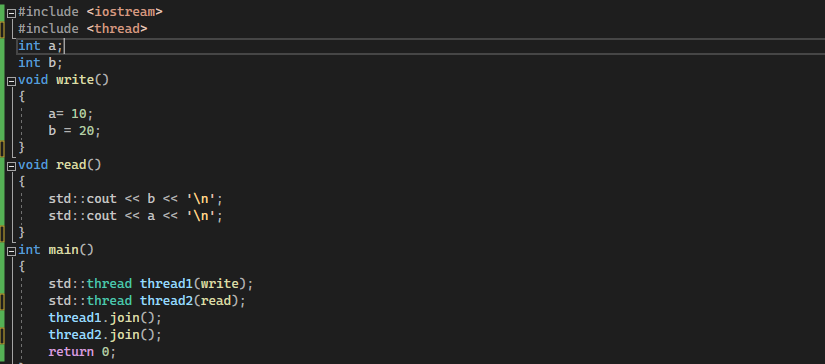
For that, we simply initiate the code by assigning two different values to two different variables of type integer. First, we initialize the variable “a” and “b” with the integer data types. Then, we create the function that is written in the void. In this function, we assign the values to both “a” and “b”, e.g. 25 and 20, respectively.
Then, we create the read function. In the read function, the values of “a” and “b” are read with the “std::cout <<a”. After creating both these functions, we now call these functions in the main thread 1 and thread 2 using “std thread (“name of the function to be called”)”. Then, we return them, come out of the main, and run the code.
Output:

The output of this example depicts the undefined behavior of the application as the code output is either 0 or 10. This happened because the threads were executing simultaneously and the read command might have been done during the execution of the write command. This way, we got an incomplete result in the output.
The std atomic can solve this problem and can make the undefined behaviors in the application well-defined. To implement this, we simply make a small change while initializing and setting the values and data types of the defined variables using “std:: atomic”. We define the variable “a” and “b” as the atomic variables by “std::atomic <datatype> variable name”. We also make a small change in the write function where, previously, we simply assigned the values to a and b using the assigning operator “=”. But here, we assign the values using the “variable name. store(value)” method. We use the “variable name. load()” in the read function. The rest is the same as in the previous example.
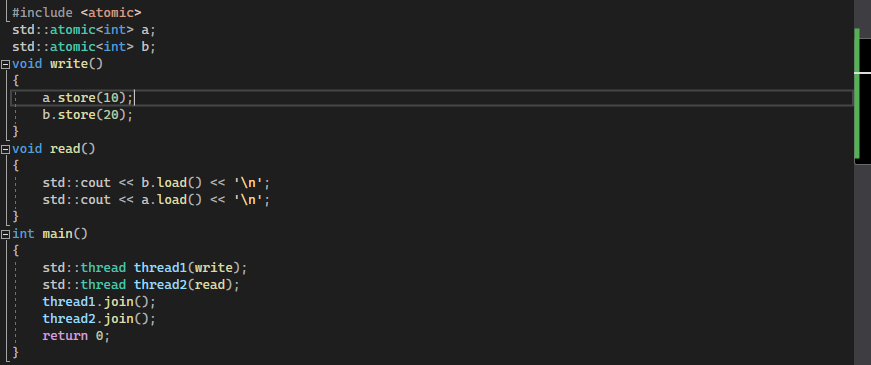

The values in the output are read and written in a well-defined way. And the multithreading is also supported here.
Release and Acquire Ordering with Memory (Model)
The memory model can have a huge impact on the read and write functions of the std atomic. The memory model is a default function that makes sure of sequential ordering consistency. One of the most interesting atomic models is the Release and Acquire model where we can store the memory order release for the first thread and the memory order acquired for the second thread, which means that any store/write either atomic or non-atomic is done first in the first thread before the second thread, i.e. load.
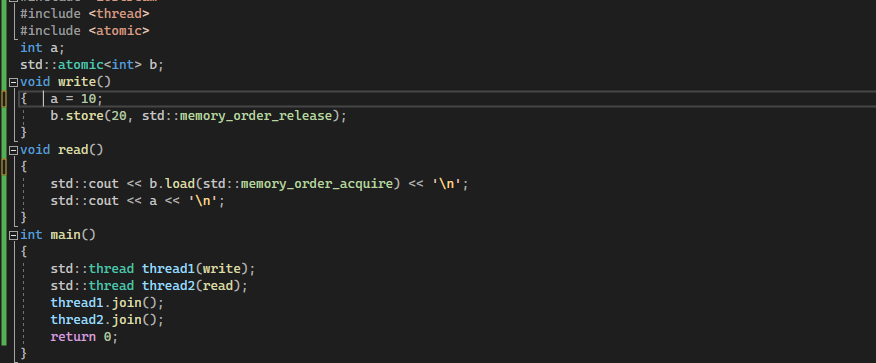
So, in the example, we can even change the one atomic variable “a” to non-atomic and the second variable “b” is kept atomic. In the write function, we store the non-atomic variable “a” simply by assigning it any value, e.g. 30. And we properly store the value for the atomic variable “b” using “b. store (value, std::memory_order_release)”. The same is done in the read function as well where we use the “std::cout <<b.load(std::memory_order_acquire) << ‘\n’” function to load the value for the atomic variable. The non-atomic variable’s value is read by a simple method. This implementation is shown in the following figure:
Output:

The atomicity of the operation is still maintained with the Release and Acquired memory model even when we had one non-atomic x variable. This happened because of the y’s (atomic.store) that made sure the maintenance of the sequential consistency.
Exchange Model
Exchange means when we swap the value of a variable (atomic) to another value. In exchange, the value is first swapped and then the previous value that is being swapped by the new one is returned. Once the value is exchanged, it reflects on every subsequent operation to that value. Let’s implement this exchange of atomic variables with the help of an example.
In this example, we first introduce the global atomic variable foobar which has some value equal to “15”. In the main, we make one thread as thread1 and assign it an integer value equal to 2. Then, in the for loop, we set the index from 0 to 100 times. Then, we replace the value of the foobar variable to 2 using “foobar. exchange(value)”. After that, we come out of the loop and load the value of the foobar variable to print it. After loading the foobar value, we now exchange its value with 18 by the “.exchange (value to be replaced with)” method. And then again, load the foobar’s values and display them using the print method.
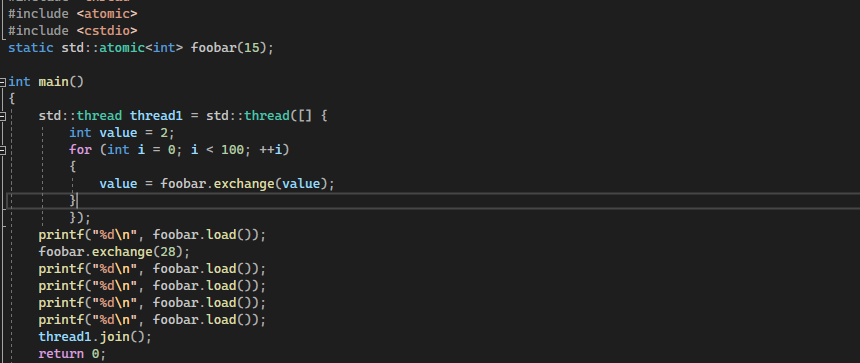
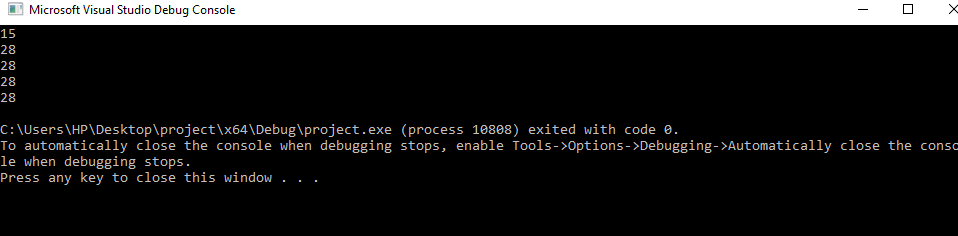
Here in this example, the thread has to exchange the values for hundred times and the value of foobar is exchanged from 15 to 28. Any operation after this exchange returns this same value as can be seen in the output.
Fetch
Fetch is the same as the exchange function that writes the values and returns the previously fetched values. This operation fetches the value tha is stored before any operation was applied to it. Now, we implement the fetch add and fetch subtract in this example. We define an atomic variable with the data type unsigned char as “count” and initialize the count with zero. Then, we create two functions – one for fetch add and another one for fetch subtract. We run the counter of increment 1 for add and decrement 1 for subtract in both of these functions. Then, we print these values from both fetch_add and fetch_sub functions in the main.
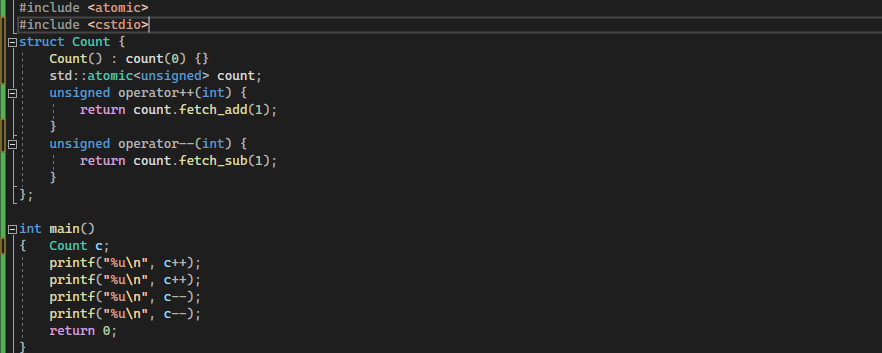

The fetch_add function returned 0 and 1 as the previous values before increment. Likewise, the fetch_sub returned 2 and 1 as the previously stored values before the subtraction or decrement of the one.
Conclusion
We implemented the basic operations in “std:: atomic” in this article. We learned how we can deal with the problems in multithreading applications using the std atomic. We implemented the various examples in C++ for the different functions like fetch, exchange, reading/writing, and memory model of the std atomic to ensure the sequential consistency and well-defined behaviors of the code for multithread applications.
Source: linuxhint.com