Batch Inference with MLflow
There are two main ways to deploy the models for batch inference with MLflow:
- Using a scoring script: A scoring script is a Python function that takes a batch of data as input and returns a batch of predictions. The scoring script can be used to deploy any model, including the models that are not supported by MLflow’s built-in model serving functionality.
- Using a model registry: A model registry is a central repository for storing and managing the machine learning models. MLflow’s model registry can be used to deploy the models that are supported by MLflow’s built-in model serving functionality.
Scenario for Batch Inference
A railway management system that uses batch processing:
The train schedules, passenger data, and ticket sales are all stored in an extensive database in the railway management system. The system must process this data in batches to generate multiple reports, update the passenger records, and send promotional emails.
The batch processing system is responsible for the following tasks:
- Generating reports: Reports regarding train schedules, passenger volume, and ticket sales are produced via the batch processing system. The railway management team might use these reports to decide on train operations and marketing initiatives.
- Updating the passenger records: If a passenger’s information changed, such as their address or preferred mode of transportation, the batch processing system updates the passengers’ records to reflect such changes.
- Sending out marketing emails: Passengers who indicated an interest in getting the marketing materials receive the emails via the batch processing system. New train services or exclusive deals are promoted in these emails.
A set schedule for the batch processing system includes once every day or once per week. The system is in charge of processing all the information that are gathered since the previous run.
Here is the complete explanation of code:
Importing the Required Libraries
Import the required libraries that are used in this code using the “import” keyword:
import mlflow
import mlflow.pyfunc
import datetime as dt
import os
from sklearn.linear_model import LinearRegression as LR
Function to Generate the Batch Data
For processing purposes, this method generates the batch data. The steps are as follows:
Use the generate_train_schedule(), generate_passenger_info(), and generate_ticket_sales() functions to generate the random train schedules, passenger information, and ticket sales statistics.
The generate_train_schedule() function generates a list of 10 random train schedules. A train ID, a start city, a stop city, and the cost of the ticket are all included in each train schedule. A list of 10 randomly chosen passenger information records is generated by the generate_passenger_info() method. A passenger ID, a title, a first name, a last name, and an age are all included in each entry of passenger information. A list of 10 randomly selected ticket sales records is created by the generate_ticket_sales() method. A train ID, a passenger ID, and the number of tickets sold are included in each record of ticket sales.
Code Snippet:
def generate_train_schedule():
train_schedules = []
for i in range(10):
train_schedules.append((
"Train {} from {} to {}".format(i, rnd.choice(["Liverpool", "Bristol", "London", "Oxford"]),
rnd.choice(["Birmingham", "Southampton", "Leicester", "Newcastle upon Tyne"])),
rnd.randint(100, 500)))
return train_schedules
# Function to generate random passenger information
def generate_passenger_info():
passenger_info = []
for i in range(10):
passenger_info.append((
"Passenger {} {} {} {}".format(i, rnd.choice(["Mr.", "Ms.", "Mrs.", "Dr."]),
rnd.choice(["Jonson", "Mary", "Peter", "Susan"]),
rnd.choice(["Christina", "Smith", "Williams", "Jones"])),
rnd.randint(18, 65)))
return passenger_info
# Function to generate random ticket sales data
def generate_ticket_sales():
ticket_sales = []
for i in range(10):
train_id = rnd.randint(0, 9)
passenger_id = rnd.randint(0, 9)
ticket_sales.append((train_id, passenger_id, rnd.randint(1, 5)))
return ticket_sales
- Create tuples by zipping the created data together.
- The timestamp is supplementary to each tuple.
- This function gives the batch data in the return statement.
The timestamp is added to each tuple to record the time when the data was created. This can be useful for auditing needs or for tracking the performance of the batch processing system over time.
railway_batch_data = []
for train_schedule, passenger_info, ticket_sales in zip(generate_train_schedule(), generate_passenger_info(), generate_ticket_sales()):
date_timestamp = dt.datetime.now() # Adding the timestamp to each data tuple
railway_batch_data.append((train_schedule, passenger_info, ticket_sales, date_timestamp))
return railway_batch_data
Function to Perform the Batch Inference
This function performs batch inference using the trained model. It takes the following steps:
- It is used for the loop to iterate through the batch of data.
- It takes the passenger age and extract it for each data point.
- It uses the trained model to predict.
- It adds the forecast to the list of forecasts.
- It gives the predictions list back. The batch_processing() function uses the perform_batch_inference() function to perform the predictions on a new batch of data. Predictions are then available for various purposes such as determining the passengers who are likely to reschedule their travel plans or forecasting how many people will board a train.
train_batch_predictions = []
for train_data in railway_batch_data:
# Assuming data[1] contains passenger ages for inference
batch_features = [train_data[1][1]] # Assuming passenger age is the second element in the passenger_info tuple
batch_prediction = model.predict([batch_features])[0] # Make predictions on a single data point
train_batch_predictions.append(batch_prediction)
return train_batch_predictions
Batch Processing Function
This function is the main entry point for the batch processing system. Here are the steps:
It trains a simple linear regression model.
A conventional linear regression model is trained by implementing the train_linear_regression_model() method. The train_features and train_labels data are employed to train the model. A list of feature vectors provides the train_features data. A single data point is represented as a list of numbers in each feature vector. There is a list of target values in the train_labels data. Each target value is a numerical representation of the result that is intended for the particular information point.
railway_model = LR()
railway_model.fit(train_features, train_labels)
return railway_model
It retrieves the new batch data that is generated since the last run.
return generate_batch_data()
It generates reports based on the batch data using the generate_reports() function.
def generate_reports(railway_batch_data):
print("Generated reports:")
for train_data in railway_batch_data:
print(train_data)
With the help of the update_passenger_records function, it updates the passenger records based on the batch data.
print("Updated passenger records:")
for train_data in railway_batch_data:
print(train_data)
It sends the marketing emails based on the batch data using the send_marketing_emails function that accepts the batch data.
print("Marketing emails to be sent:")
for train_data in railway_batch_data:
print(train_data)
Optionally, it logs the batch data or any other relevant information to MLflow for tracking purposes.
A nice illustration on how to use Python to construct a batch processing system is the batch_processing() function. It is simple to learn, is modular, and adaptable enough to satisfy the particular requirements in the application. This function also shows how to track the batch processing runs using MLflow.
Code Snippet:
# Train a simple linear regression model (replace this with your actual model training code)
train_features = [[rnd.randint(18, 65)] for _ in range(100)]
train_labels = [rnd.randint(100, 500) for _ in range(100)]
railway_model = train_linear_regression_model(train_features, train_labels)
# Retrieve new batch data since the last run
railway_batch_data = get_batch_data()
# Generate reports based on the batch data
generate_reports(railway_batch_data)
# Update passenger records based on the batch data
update_passenger_records(railway_batch_data)
# Send marketing emails based on the batch data
send_marketing_emails(railway_batch_data)
# Optional: Save the batch data or any other relevant information for tracking purposes
# For example, you can log the batch data to MLflow to keep track of batch processing runs.
for i, train_data in enumerate(railway_batch_data):
with mlflow.start_run(nested=True): # Create a new nested run for each data point
mlflow.log_param("Train Schedule Data", train_data[0])
mlflow.log_param("Passenger Info Data", train_data[1])
mlflow.log_param("Ticket Sales Data", train_data[2])
mlflow.log_param("Timestamp", train_data[3])
train_prediction = perform_batch_inference(railway_model, [train_data])
mlflow.log_metric("Predicted Passenger Age", train_prediction[0])
Main Function of the Program
The if __name__ == “__main__”: statement, the os.environ[“GIT_PYTHON_REFRESH”] = “quiet” line, and the batch_processing() function are all important parts of the batch processing script. They allow the script to be run as a script and suppress the Git warning, and they provide the main entry point for the batch processing system.
# Set the GIT_PYTHON_REFRESH environment variable to "quiet" to suppress the Git warning
os.environ["GIT_PYTHON_REFRESH"] = "quiet"
batch_processing()
Output of the Code:
After the successful execution of the code on the command line using Python, the following output is generated:
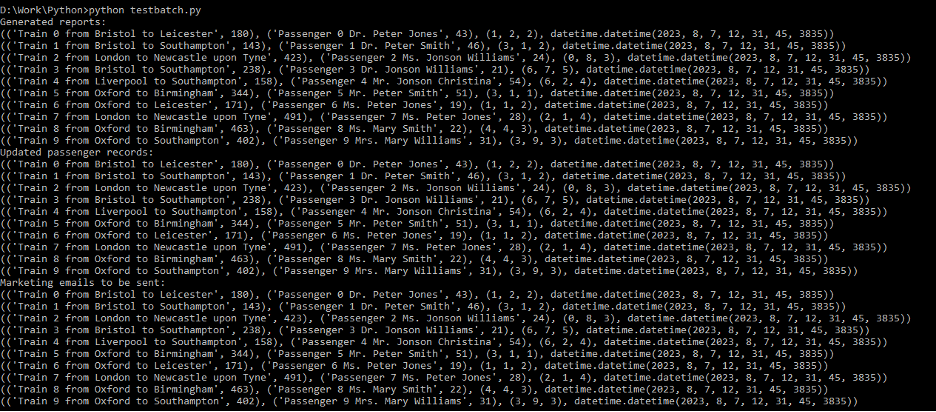
Conclusion
Batch inference in MLflow is a way to perform an inference on a large dataset using a trained model. This can be helpful for tasks like producing reports, modifying records, and bulk sharing of information. Using MLflow, the batch data can be logged. This can be helpful for batch processing system monitoring, debugging, and auditing. Through the central repository of MLflow, the batch processing runs can be observed. As a result, tracking the usefulness of batch processing systems over time is trivial. With MLflow, the trained models may be deployed in various production scenarios. This makes establishing a batch inference system in deployment easy.
Source: linuxhint.com