16 Bash Regular Expression (RegEx) Examples Using grep, sed, and awk Commands
Regular Expression or Regex is a sequence of special characters that form a pattern to find specific pattern-matching instances from a file and manipulate them. It is mainly used for searching specific characters, words, filtering, or text manipulation in a file.
Regex is largely used in programming languages including in Linux Bash scripting. In this guide, I will cover how to use regex in Bash, the main regular expressions, and how to use various regex processing engines.
- What is Regex
- Regex Versions
- Syntax of Regex
- Components of Regex Syntax
- 16 Examples of Using Regex in Linux
- Regex Cheat Sheet
- Conclusion
What is Regex
The regular expression or regex in Linux is a pattern made up of special metacharacters to match the specific pattern in a string or text file.
Let’s understand it with a real-life example, suppose you want to write a code to find some specific variables and then manipulate them in another code file then you may need regular expression in such a situation.
Regex Versions
There are different versions of regex and it is important to note that not all regex processor commands support all the regex.
- Basic Regular Expression (BRE)
- Extended Regular Expression (ERE)
- Perl Compatible Regular Expression (PCRE)
The BRE and ERE are further classified as:
- POSIX BRE/ERE
- GNU BRE/ERE
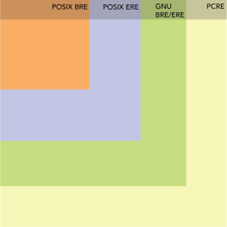
POSIX BRE and POSIX ERE are subsets of GNU BRE and ERE and GNU BRE/ERE is a subset of PCRE.
Syntax of Regex
Different command-line utilities are used with regular expressions, such as:
- grep
- sed
- awk
These commands are also called regex engines which help in translating complex regular expressions and give the output.
Regex Syntax with grep
Regex Syntax with sed
Regex Syntax with awk
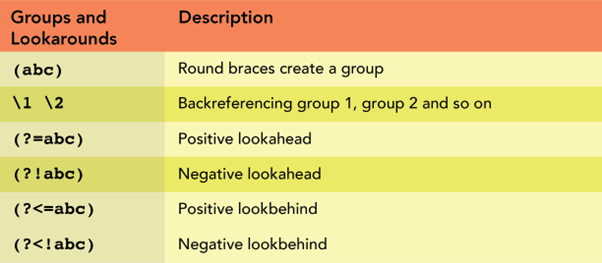
Components of Regex Syntax
There are six main components of regular expression syntax:
- Characters
- Metacharacters
- Quantifiers
- Character Classes
- Grouping
- Lookarounds
Characters: These components form patterns using any single characters or multiple characters to search for exact patterns in the string or file. For example, the character H will search for H in the file, similarly, the letters Linux will search exact Linux word in the file. However, -i flag can be used to make search case-insensitive.
Metacharacters: These components contain special characters and have specific functionality. For example, the dot metacharacter is used to find the character, while ^ match the start of the line while $ match the end of the line. Another metacharacter pipe a|b is used to match a and b in the file.
Quantifiers: These components are used to find how many times a specific pattern must be repeated. For example, the question mark ? repeats the preceding character only zero or one time on the other asterisk find the preceding character zero or more times.
Character Classes: The groups of characters enclosed in the square brackets ([]) are known as character class components. For example, [0-9] indicates numbers from 0 to 9, similarly [A-Z] indicates all the alphabets from A to Z in capital.
Grouping: This component helps in grouping the pattern into round brackets (). It is especially useful to find repeating sequences like phone numbers or email addresses.
Lookarounds: This component is used to make a positive and negative look around a pattern preceded or succeeded by another pattern. For example, a(?=b) will look for all the a‘s if they come before b.
16 Examples of Using Regex in Linux
The following examples cover the usage of various metacharacters, quantifiers, groups, and some unique patterns.
Example 1: Using Dot (.) Expression
The dot is the basic metacharacter of regular expression used to match a single character. For example:
Using grep:
Using sed:
Using awk:
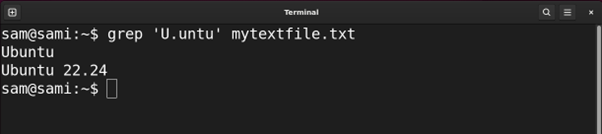
Example 2: Using Caret (^) Expression
The caret ^ metacharacter is used to find all the lines starting from the given pattern. For example:
Using grep:
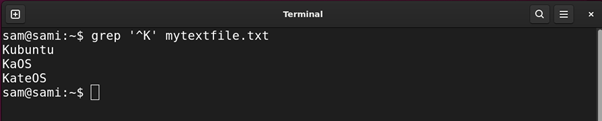
Using sed:
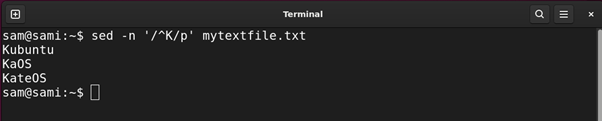
Using awk:
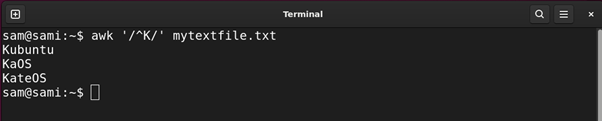
The above commands print out all the entries in the file starting from K.
Example 3: Using Dollar ($) Expression
This metacharacter is used to find all the string ends with the specific character. For example:
Using grep:
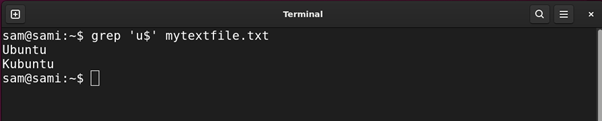
Using sed:
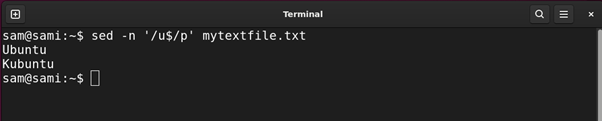
Using awk:
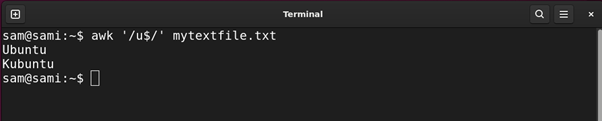
The above commands give all the strings in the file ending with u.
Example 4: Using Asterisk (*) Expression
The asterisk * quantifier matches the occurrence of the preceding characters in the string zero or more times. It is equivalent to {0,}. For example:
Using grep:
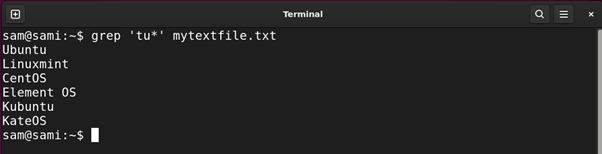
Using sed:
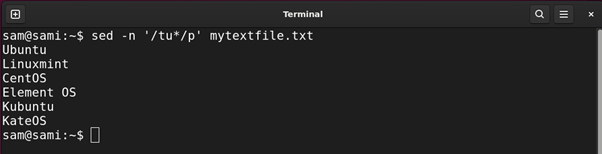
Using awk:
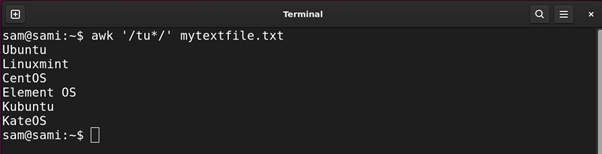
Example 5: Using Question Mark (?) Expression
The question mark (?) quantifier is used to search whether the preceding character occurs zero or one time only. It acts as an optional qualifier.
Using grep:
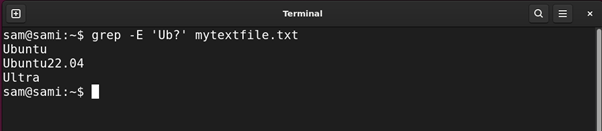
The -E in the above command is for extended regex.
Using sed:
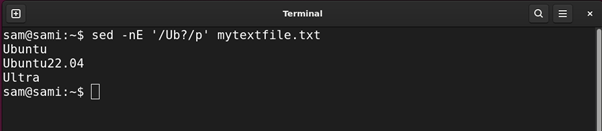
The -E in the above command is for extended regex.
Using awk:
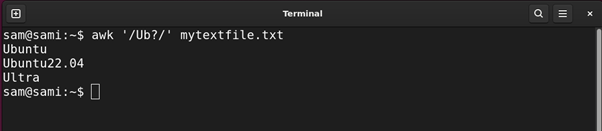
The difference between the asterisk and question mark quantifiers is mentioned in the image below:
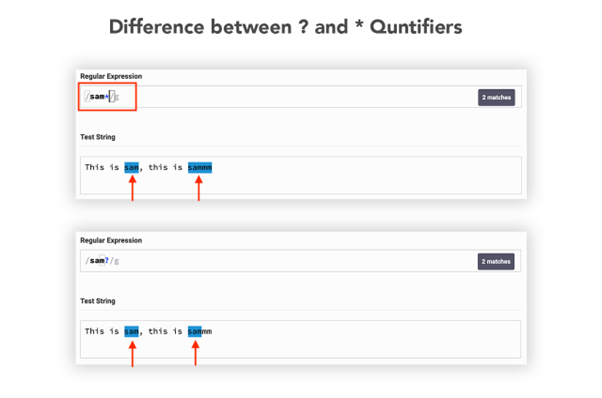
The asterisk searches all the characters matching with the preceding character while the question mark of the preceding character is matched only on time.
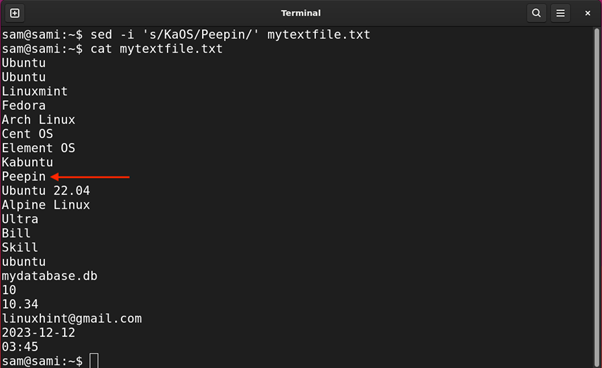
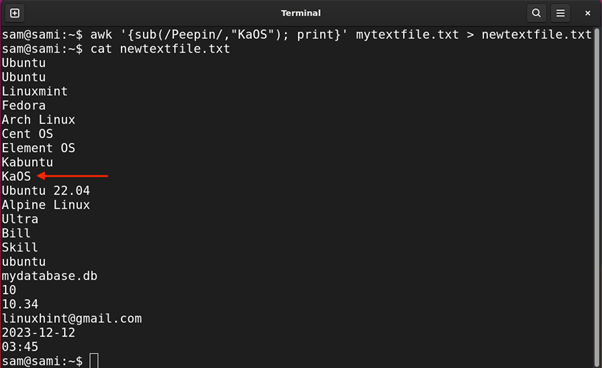
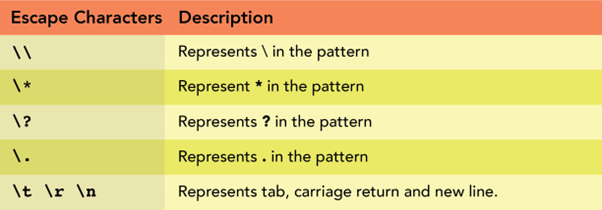
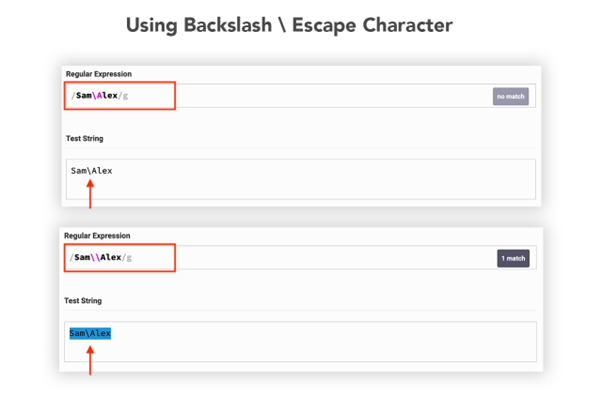
Example 6: Using Backslash (\) Expression
This backslash \ metacharacter is used to represent the special character. For example, the asterisk * itself is a special character to use asterisk literally we will use backslash.
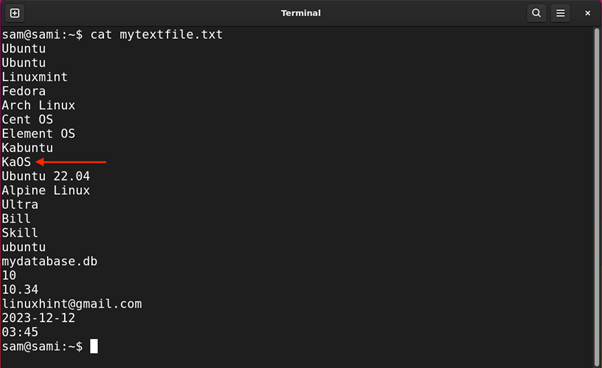
Let’s find all the Linux distributions in the file mytextfile.txt with space in their names.
Using grep:
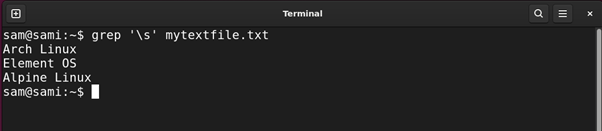
Using sed:
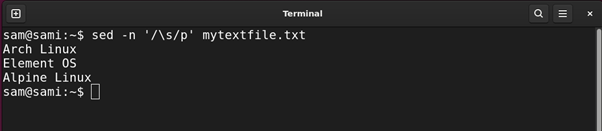
Using awk:
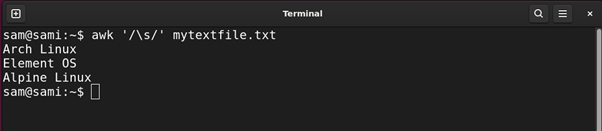
Moreover, the backslash is also used with other various escape characters.
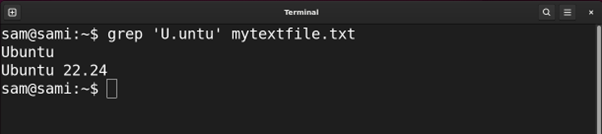
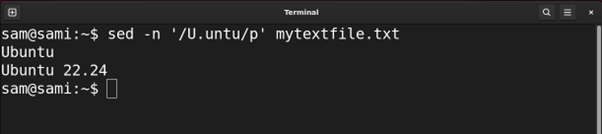
Example 7: Creating a Group of Patterns Using Round Braces ()
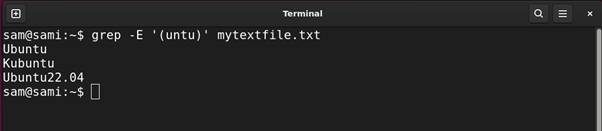
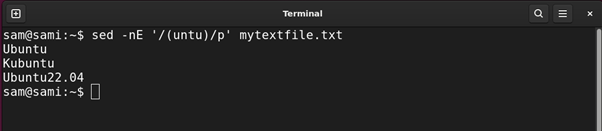
The round braces () are used to match the group of expressions inside them. Let’s understand it with an example:
Using grep:
Using sed:
Using awk:
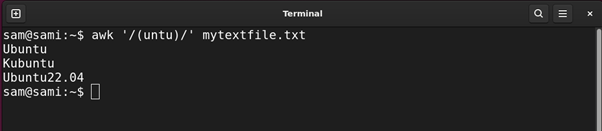
In the above commands, the engine is grabbing entries with match with the group (untu). The group can also be used with another pattern followed by it. For example, if we replace the (untu) group with (unt)u the result will be the same.
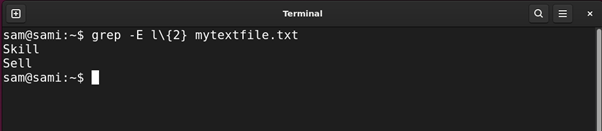
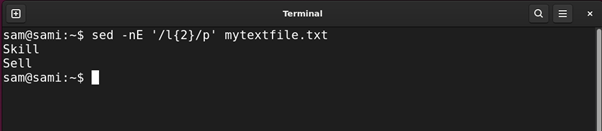
Example 8: Creating Ranged Patterns Using Curly Braces {} Expression
The curly braces {} are repetition quantifiers. You can use them in 3 different ways:
{x}: Appearing x number of times
{x,y} or {min,max}: Appearing x number of times but not more than y
{x,}: Appearing x number of times and more
Using grep:
Using sed:
Using awk:

The above command finds entries that contain the character l twice such as Bill and Skill.
Example 9: Using \d to Find Numerals
The \d expression is used to find the string with numerals in a string or file. For example:
Using grep:

P indicates that it is a Perl-compatible regex, for more details read here.
In sed and awk, \d cannot be used because sed is POSIX regex and not Perl PCRE, therefore, the equivalent to \d in sed and awk is [0-9] or [[:digit:]].
Using sed:

Or:

Using awk:

Or:

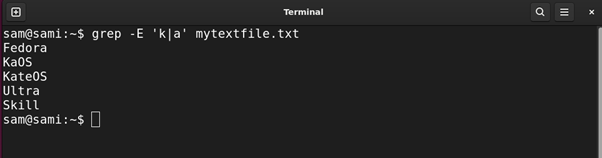
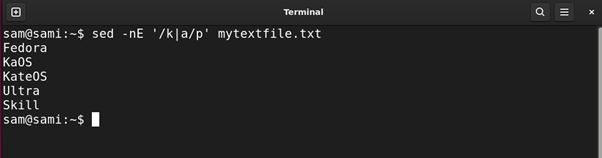
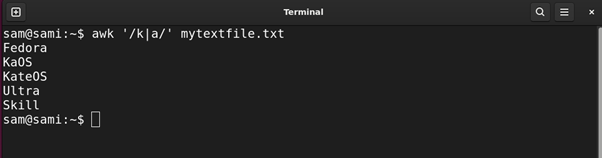
Example 10: Using Logical OR Operator |
The | regular expression works the same way the logical OR gate works. For example, if we use a|o then this pattern will find all the words containing either a character or o character.
Using grep:
Using sed:
Using awk:
Example 11: Finding all the Words with a Specific Number of Characters
To find all the words with a specific number of characters we can use a dot (.). The dot metacharacter is used to find one character but it can also be used to search multiple characters. To find all the lines with four characters, use:
Using grep:

Using sed:

Using awk:

Example 12: Finding IP Address From a File
The IP address is one of the key items that you want to extract from a file using regex. Since an IP address contains dots, finding it using regex is not a straightforward operation: we have to escape the dot (.) using slash. Let’s extract IP addresses from the /etc/hosts file.
Using grep:

Or: